I'm trying to read this github Json (url below) with information from football teams, games and players
Here's my sample code:
import json
import pandas as pd
import urllib.request
from pandas import json_normalize
load_path = 'https://raw.githubusercontent.com/henriquepgomide/caRtola/master/data/2021/Mercado_10.txt'
games_2021 = json.loads(urllib.request.urlopen(load_path).read().decode('latin-1'))
games_2021 = json_normalize(games_2021)
games_2021
The bad output:

The desired output can be seen in the code below:
pd.read_csv('https://raw.githubusercontent.com/henriquepgomide/caRtola/master/data/2022/rodada-0.csv')
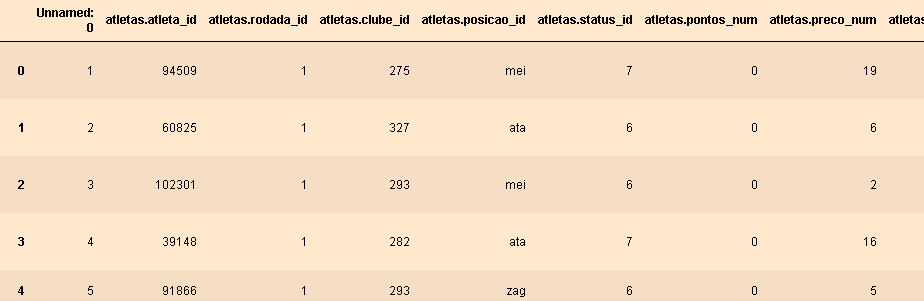
Both urls contain the same information, but the JSON file is in a dictionary schema I guess, where the initial information is translating some of the values columns for players and teams can have, while the other link is already cleaned somehow, in a Csv structure.
CodePudding user response:
Just normalize the 'atleta' key in the json. Or simply just construct that into a DataFrame.
import json
import requests
import pandas as pd
load_path = 'https://raw.githubusercontent.com/henriquepgomide/caRtola/master/data/2021/Mercado_10.txt'
jsonData = requests.get(load_path).json()
games_2021 = pd.json_normalize(jsonData['atletas'])
cols = [x for x in games_2021.columns if 'scout.' not in x]
games_2021 = games_2021[cols]
OR
import json
import requests
import pandas as pd
load_path = 'https://raw.githubusercontent.com/henriquepgomide/caRtola/master/data/2021/Mercado_10.txt'
jsonData = requests.get(load_path).json()
games_2021 = pd.DataFrame(jsonData['atletas']).drop('scout', axis=1)
Output:
print(games_2021)
atleta_id ... foto
0 83817 ... https://s.glbimg.com/es/sde/f/2021/06/04/68300...
1 95799 ... https://s.glbimg.com/es/sde/f/2020/07/28/e1784...
2 81798 ... https://s.glbimg.com/es/sde/f/2021/04/19/7d895...
3 68808 ... https://s.glbimg.com/es/sde/f/2021/04/19/ca9f7...
4 92496 ... https://s.glbimg.com/es/sde/f/2020/08/28/8c0a6...
.. ... ... ...
755 50645 ... https://s.glbimg.com/es/sde/f/2021/06/04/fae6b...
756 69345 ... https://s.glbimg.com/es/sde/f/2021/05/01/0f714...
757 110465 ... https://s.glbimg.com/es/sde/f/2021/04/26/a2187...
758 111578 ... https://s.glbimg.com/es/sde/f/2021/04/27/21a13...
759 38315 ... https://s.glbimg.com/es/sde/f/2020/10/09/a19dc...
[760 rows x 15 columns]
Then just a matter of reading in each table and merge to get the full:
import json
import requests
import pandas as pd
load_path = 'https://raw.githubusercontent.com/henriquepgomide/caRtola/master/data/2021/Mercado_10.txt'
jsonData = requests.get(load_path).json()
atletas = pd.DataFrame(jsonData['atletas']).drop('scout', axis=1)
clubes = pd.DataFrame(jsonData['clubes'].values())
posicoes = pd.DataFrame(jsonData['posicoes'].values())
status = pd.DataFrame(jsonData['status'].values())
df = atletas.merge(clubes, how='left', left_on='clube_id', right_on='id', suffixes=['', '_clube'])
df = df.merge(posicoes, how='left', left_on='posicao_id', right_on='id', suffixes=['', '_posicao'])
df = df.merge(status, how='left', left_on='status_id', right_on='id', suffixes=['', '_status'])