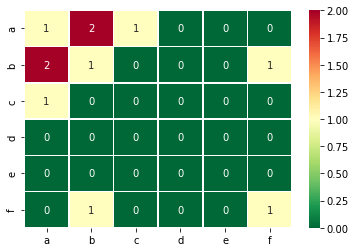
I'm a little bit stuck. I habe a Dataframe with a list in a column.
| id | list |
|---|---|
| 1 | [a, b] |
| 2 | [a,a,a,b] |
| 3 | c,b,b |
| 4 | [c,a] |
| 5 | [f,f,b] |
I have the values, a, b, c, d, e, f in general. I want to count if two values are in a list togehter and also if a value appears more than once in that list.
I want to get that to create a heatmap, with all values in x and y axis. and the counts where e.g. a is x times in a list with itself or e.g. a and b are x times togehter.
I tried this so far, but it is not exactly the solution i want.
Make ne columns and count values
df['a'] = df['list'].explode().str.contains('a').groupby(level=0).any().astype('int')
df['b'] = df['list'].explode().str.contains('b').groupby(level=0).any().astype('int')
df['c'] = df['list'].explode().str.contains('c').groupby(level=0).any().astype('int')
df['d'] = df['list'].explode().str.contains('d').groupby(level=0).any().astype('int')
df['e'] = df['list'].explode().str.contains('e').groupby(level=0).any().astype('int')
df['f'] = df['list'].explode().str.contains('f').groupby(level=0).any().astype('int')
here i get the first problem, i create a new df with rows names the list and counting the values in the list, but I also get the count if i only have the value once in the list
make x axis
df_explo = df.explode(['list'],ignore_index=True)
get sum of all
df2=df_explo.groupby(['list']).agg({'a':'sum','b':'sum','c':'sum','d':'sum','e':'sum','f':'sum').reset_index()
set index to list
df3 = df2.set_index('list')
create heatmap
sns.heatmap(df3,cmap='RdYlGn_r', linewidths=0.5,annot=True,fmt="d")
CodePudding user response:
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from collections import Counter
from itertools import combinations
data = [
['a', 'b'],
['a', 'a', 'a', 'b'],
['b', 'b', 'b'],
['c', 'a'],
['f', 'f', 'b']
]
letters = ['a', 'b', 'c', 'd', 'e', 'f']
duplicate_occurrences = pd.DataFrame(0, index=[0], columns=letters)
co_occurrences = pd.DataFrame(0, index=letters, columns=letters)
for l in data:
duplicates = [k for k, v in Counter(l).items() if v > 1]
for d in duplicates:
duplicate_occurrences[d] = 1
co = list(combinations(set(l), 2))
for a, b in co:
co_occurrences.loc[a, b] = 1
co_occurrences.loc[b, a] = 1
plt.figure(figsize=(7, 1))
sns.heatmap(duplicate_occurrences, cmap='RdYlGn_r', linewidths=0.5, annot=True, fmt="d")
plt.title('Duplicate Occurrence Counts')
plt.show()
sns.heatmap(co_occurrences, cmap='RdYlGn_r', linewidths=0.5, annot=True, fmt="d")
plt.title('Co-Occurrence Counts')
plt.show()

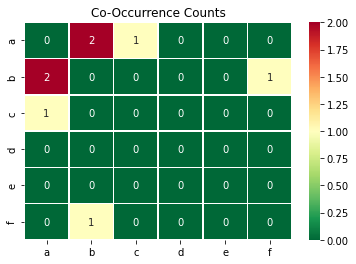
The first plot shows how often each letter occurs at least twice in a list, the second shows how often each pair of letters occurs together in a list.
In case you want to plot the duplicate occurrences on the diagonal, you could do it e.g. as follows:
df = pd.DataFrame(0, index=letters, columns=letters)
for l in data:
for k, v in Counter(l).items():
if v > 1:
df.loc[k, k] = 1
for a, b in combinations(set(l), 2):
df.loc[a, b] = 1
df.loc[b, a] = 1
sns.heatmap(df, cmap='RdYlGn_r', linewidths=0.5, annot=True, fmt="d")