I'm trying to scrape this 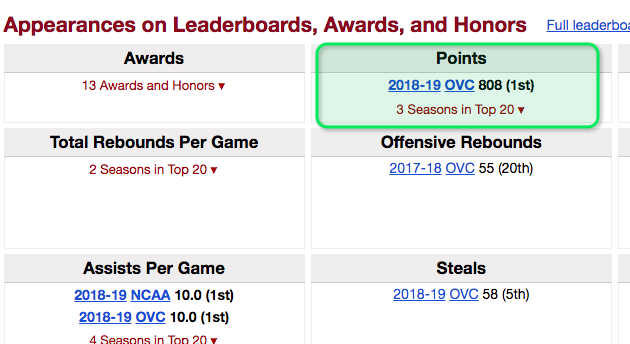
I can see where this part of the website is when I inspect the page:
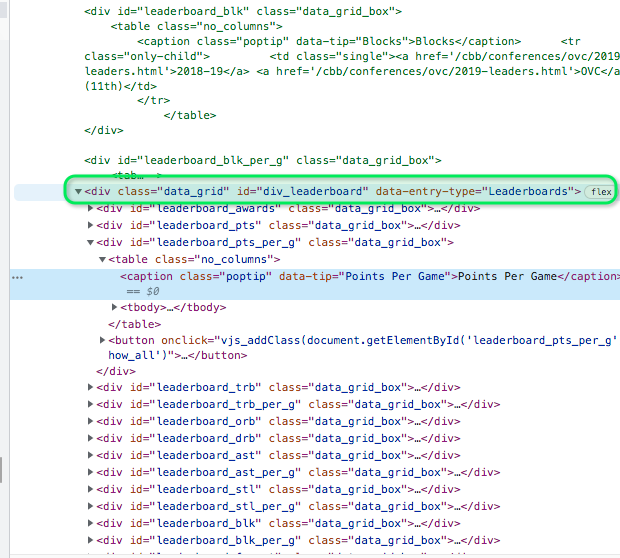
But I can't get to it from BeautifulSoup.
Here is the code that I'm using and all the ways I've tried to access it:
from bs4 import BeautifulSoup
import requests
link = 'https://www.sports-reference.com/cbb/players/temetrius-morant-1.html'
html_text = requests.get(link).text
soup = BeautifulSoup(html_text, 'html.parser')
soup.find_all(class_='data_grid')
soup.find_all(string="data_grid")
soup.find_all(attrs={"class": "data_grid"})
Also, when I just look at the html I can see that it is there:
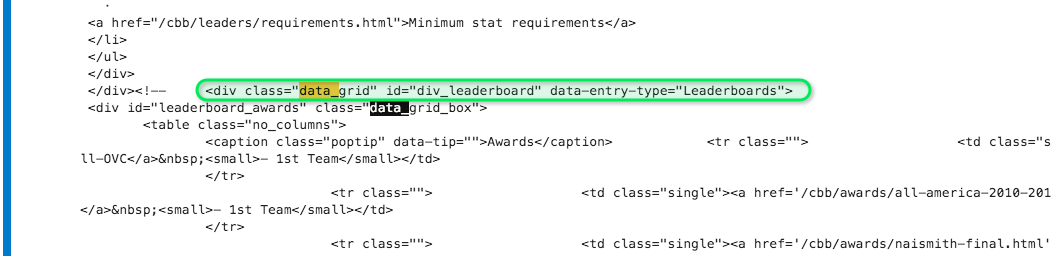
CodePudding user response:
if you re looking for the point section i suggest to search with id like this:
point_section=soup.find("div",{"id":"leaderboard_pts"})
CodePudding user response:
You need to look at the actual source html code that you get in response (not the html you inspect, which you have shown to have done), you'll notice those tables are within the comments of the html Ie. <!-- and -->. BeautifulSoup ignores comments.
There are a few ways to go about it. BeautifulSoup does have a method to search and pull out comments, however with this particular site, I find it just easier to remove the comment tags.
Once you do that, you can easily parse the html with BeautifulSoup to get the desired <div> tag, then just let pandas parse the <table> tag within there.
import requests
import pandas as pd
from bs4 import BeautifulSoup
url = 'https://www.sports-reference.com/cbb/players/temetrius-morant-1.html'
response = requests.get(url)
html = response.text
html = html.replace('<!--', '').replace('-->', '')
soup = BeautifulSoup(html, 'html.parser')
leaderboard_pts = soup.find('div', {'id':'leaderboard_pts'})
df = pd.read_html(str(leaderboard_pts))[0]
Output:
print(df)
0
0 2017-18 OVC 405 (18th)
1 2018-19 NCAA 808 (9th)
2 2018-19 OVC 808 (1st)