I have two dataframes:
df_A = pd.DataFrame({'start_date':['2022-07-01 00:02:41','2022-07-01 00:07:41','2022-07-01 00:22:41','2022-07-01 01:01:23','2022-07-01 01:01:23'],'end_date':['2022-07-01 00:02:41','2022-07-01 00:17:41','2022-07-01 00:57:42','2022-07-01 01:01:23','2022-07-01 01:03:51',], 'eventname':['e2','e3','e5','e6','e7',] })
df_B = pd.DataFrame({'start_date':['2022-07-01 00:00:41','2022-07-01 00:06:41','2022-07-01 00:17:56','2022-07-01 01:03:40',],'end_date':['2022-07-01 00:01:41','2022-07-01 00:14:41','2022-07-01 00:19:42','2022-07-01 02:03:23',], 'eventname':['e1','e3','e4','e7',] })
#df_A
start_date end_date eventname
0 2022-07-01 00:02:41 2022-07-01 00:02:41 e2
1 2022-07-01 00:07:41 2022-07-01 00:17:41 e3
2 2022-07-01 00:22:41 2022-07-01 00:57:42 e5
3 2022-07-01 01:01:23 2022-07-01 01:01:23 e6
4 2022-07-01 01:01:23 2022-07-01 01:03:51 e7
#df_B
start_date end_date eventname
0 2022-07-01 00:00:41 2022-07-01 00:01:41 e1
1 2022-07-01 00:06:41 2022-07-01 00:14:41 e3
2 2022-07-01 00:17:56 2022-07-01 00:19:42 e4
3 2022-07-01 01:03:40 2022-07-01 02:03:23 e7
I would like to join the rows of df_B to df_A if the time interval has any overlap and my expected result is this:
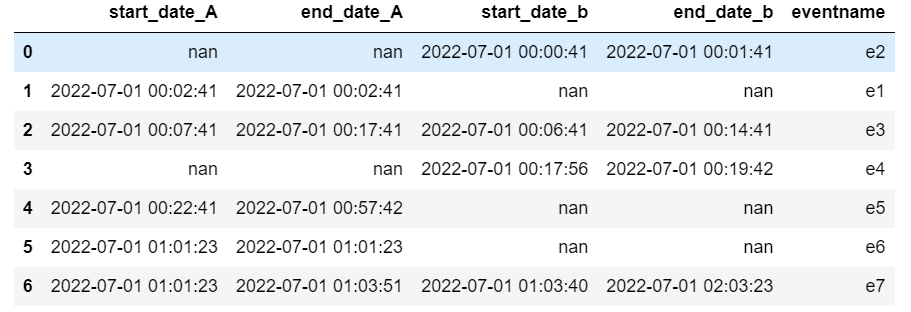
df_C = pd.DataFrame({'start_date_A':['nan','2022-07-01 00:02:41','2022-07-01 00:07:41','nan','2022-07-01 00:22:41','2022-07-01 01:01:23','2022-07-01 01:01:23',],'end_date_A':['nan','2022-07-01 00:02:41', '2022-07-01 00:17:41','nan','2022-07-01 00:57:42','2022-07-01 01:01:23','2022-07-01 01:03:51',],'start_date_b':['2022-07-01 00:00:41','nan','2022-07-01 00:06:41','2022-07-01 00:17:56','nan','nan','2022-07-01 01:03:40',],'end_date_b':['2022-07-01 00:01:41', 'nan', '2022-07-01 00:14:41', '2022-07-01 00:19:42', 'nan', 'nan', '2022-07-01 02:03:23', ], 'eventname':['e2','e1','e3','e4','e5','e6','e7'] })
#df_C
I tried the solution mentioned here but it gives me only the first value of the column each time, not the value for that row.
I also tried using the IntervalIndex like this:
bins = pd.IntervalIndex.from_arrays(df_A['start_date'],
df_A['end_date'],
closed='both')
out = df_B.assign(interval=pd.cut(df_B['eventname'], bins)) \
.merge(df_A.assign(interval=bins), on='interval', how='left')
but I get the error that overlapping intervals are not allowed. How can I do this?
Edit: eventname also need to be the same for the join to happen. If not, both the rows have to be present separately so it will be a full join
CodePudding user response:
Do full join on eventname and then split rows where time intervals do not overlap:
df_A.start_date = pd.to_datetime(df_A.start_date)
df_A.end_date = pd.to_datetime(df_A.end_date)
df_B.start_date = pd.to_datetime(df_B.start_date)
df_B.end_date = pd.to_datetime(df_B.end_date)
df = df_A.set_index("eventname").join(df_B.set_index("eventname"), how="outer", lsuffix="_a", rsuffix="_b")
def overlap_processing(row: pd.Series):
if (
(row.start_date_a <= row.start_date_b <= row.end_date_a)
or (row.start_date_a <= row.end_date_b <= row.end_date_a)
or row.isna().any()
):
return row
else:
return pd.Series(
{
"start_date_a": [row.start_date_a, pd.NaT],
"end_date_a": [row.end_date_a, pd.NaT],
"start_date_b": [pd.NaT, row.start_date_b],
"end_date_b": [pd.NaT, row.end_date_b],
}
)
result = df.apply(overlap_processing, axis=1).explode(list(df.columns)).reset_index()
CodePudding user response:
import pandas as pd
df_A = pd.DataFrame({'start_date':['2022-07-01 00:02:41','2022-07-01 00:07:41','2022-07-01 00:22:41','2022-07-01 01:01:23','2022-07-01 01:01:23'],'end_date':['2022-07-01 00:02:41','2022-07-01 00:17:41','2022-07-01 00:57:42','2022-07-01 01:01:23','2022-07-01 01:03:51',], 'eventname':['e2','e3','e5','e6','e7',] })
df_B = pd.DataFrame({'start_date':['2022-07-01 00:00:41','2022-07-01 00:06:41','2022-07-01 00:17:56','2022-07-01 01:03:40',],'end_date':['2022-07-01 00:01:41','2022-07-01 00:14:41','2022-07-01 00:19:42','2022-07-01 02:03:23',], 'eventname':['e1','e3','e4','e7',] })
df_A.rename(columns={'start_date': 'start_date_A', 'end_date': 'end_date_A'}, inplace=True)
df_B.rename(columns={'start_date': 'start_date_B', 'end_date': 'end_date_B'}, inplace=True)
df1 = pd.concat([df_A, df_B]) # or df_A.append(df_B)
# reset index
df1.reset_index(drop=True, inplace=True)
df1.info()
df1
Output-
start_date_A end_date_A eventname start_date_B end_date_B
0 2022-07-01 00:02:41 2022-07-01 00:02:41 e2 NaN NaN
1 2022-07-01 00:07:41 2022-07-01 00:17:41 e3 NaN NaN
2 2022-07-01 00:22:41 2022-07-01 00:57:42 e5 NaN NaN
3 2022-07-01 01:01:23 2022-07-01 01:01:23 e6 NaN NaN
4 2022-07-01 01:01:23 2022-07-01 01:03:51 e7 NaN NaN
5 NaN NaN e1 2022-07-01 00:00:41 2022-07-01 00:01:41
6 NaN NaN e3 2022-07-01 00:06:41 2022-07-01 00:14:41
7 NaN NaN e4 2022-07-01 00:17:56 2022-07-01 00:19:42
8 NaN NaN e7 2022-07-01 01:03:40 2022-07-01 02:03:23