I have just started exploring execution plans in SQL and I am not able to figure out how the query optimizer decides when to do a full table scan or index scan.
I ran several queries on the DB available in 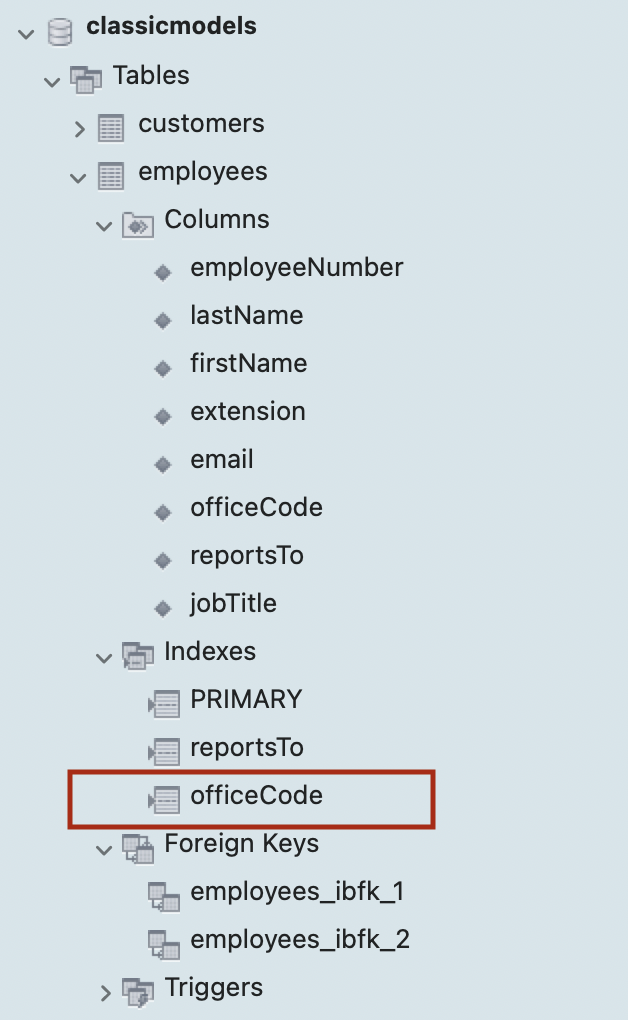
I guessed an index scan using officeCode would suffice, but, according to the execution plan, a full table scan was performed.
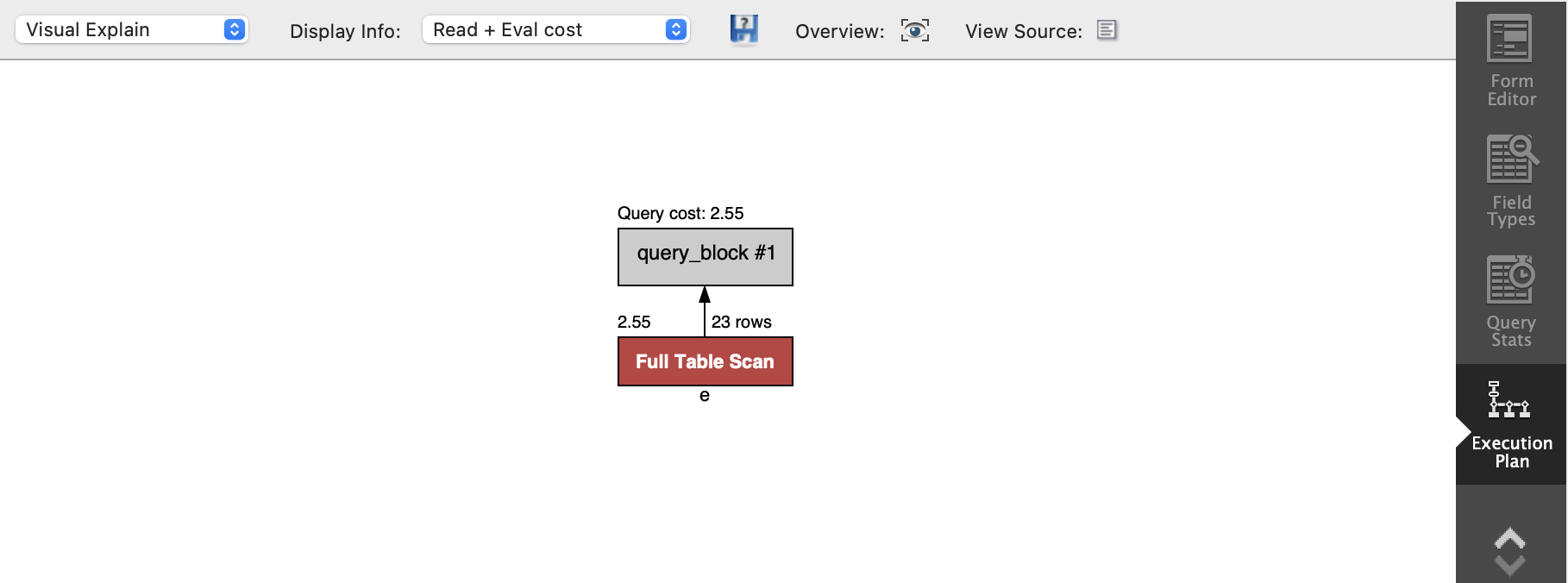
Can someone please explain why a full table scan was performed instead of an index scan?
CodePudding user response:
The most common reason is that the optimizer estimates that using the index will in fact be more costly than simply reading all the rows.
If the specific value you're searching for (in this case officeCode value of 1) occurs on a large enough subset of rows, the optimizer decides that reading the index entries only to then be redirected to the table rows is a waste of time. For the same reason that very common words are not included in the index at the back of a book.
Another factor is that the data is read into RAM in pages, so if your table is quite small, it's likely to fit all rows onto a single page. Once the search is narrowed down to a single page, the benefit of an index is trivial. Since data is stored on a different page than the index, using an index could even result in reading more pages than just doing the table-scan on a single page.
Your visual EXPLAIN shows that the number of rows examined by the table-scan is about 23 rows, so I would guess that these might reside on one page.
You might like to read https://dev.mysql.com/doc/refman/8.0/en/cost-model.html