I am new to Pandas. I have a dataframe and would like to split df -
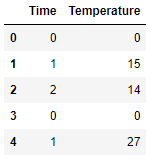
The output should look like this -
df1 -
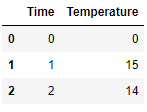
df2 -
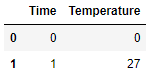
Basically the dataframe must be split where my entire row values are 0. A for loop approach would be appreciated as my dataframe has many rows and many rows with 0 values Any help would be really appreciated.
CodePudding user response:
You can check if all values in a row are 0, and use this to construct a custom group for splitting:
out = [g for _,g in df.groupby(df.eq(0).all(1).cumsum())]
output (list of DataFrames):
[ Time Temperature
0 0 0
1 1 15
2 2 14,
Time Temperature
3 0 0
4 1 27]
intermediates:
Time Temperature .eq(0).all(1) cumsum
0 0 0 True 1
1 1 15 False 1
2 2 14 False 1
3 0 0 True 2
4 1 27 False 2
CodePudding user response:
You wouldn't be able to split your original dataframe into your examples for df1, df2, or df3, but that's because with the examples you've given, each of those outputs have at least one row that didn't exist in the original. If you're trying to perform some calculations in addition to the splitting, it's not clear to me.
I'm guessing you're referring to indexing and selecting data (the Pandas documentation lists a lot of options). I'll assume you want all the columns and just want to filter out certain rows. Given your original dataframe:
>>> import pandas as pd
>>> df = pd.DataFrame({'Time': [0, 1, 2, 0, 0, 1], 'Temperature':[10, 15, 14, 15, 17, 18]})
Time Temperature
0 0 10
1 1 15
2 2 14
3 0 15
4 0 17
5 1 18
You could use iloc() for index-based slicing:
>>> df.iloc[0:2]
Time Temperature
0 0 10
1 1 15
You could use loc(), which is different from iloc() since it allows for label-based slicing:
>>> df.loc[0:2, ['Time', 'Temperature']]
Time Temperature
0 0 10
1 1 15
2 2 14
If your indexes were string labels, then loc works great there as well...here's an example from the Pandas documentation:
>>> df = pd.DataFrame([[1, 2], [4, 5], [7, 8]],
index=['cobra', 'viper', 'sidewinder'],
columns=['max_speed', 'shield'])
>>> df
max_speed shield
cobra 1 2
viper 4 5
sidewinder 7 8
>>> df.loc[['viper', 'sidewinder']]
max_speed shield
viper 4 5
sidewinder 7 8
And you could use boolean indexing. Using a Python comparison operator, you'd get a Pandas series of type boolean. You can pass that into a dataframe with square brackets and it'll only return whatever is True:
>>> df['Time'] == 0
0 True
1 False
2 False
3 True
4 True
5 False
Name: Time, dtype: bool
>>> df[df['Time'] == 0]
Time Temperature
0 0 10
3 0 15
4 0 17
Anyways, there's a lot of different options and here were just a few. Definitely check out the documentation and see what would work best for your application.