I'm having an issue loading the Boston dataset with pandas. It seems like it't not recognizing the continuing/newlines. What am I missing?
python 3.9.0
pandas 1.3.5
import pandas as pd
pd.read_csv(filepath_or_buffer="http://lib.stat.cmu.edu/datasets/boston", sep=" ", skiprows=21)
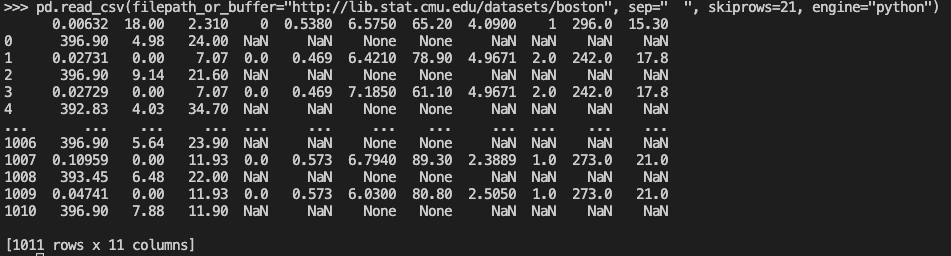
CodePudding user response:
I don't know a good way to read in a table which has it's rows on multiple lines. Here's an approach that reads in the table, converts it to a single list of values, drops the nulls, and reshapes to have a new table with the correct number of columns
import pandas as pd
import numpy as np
df = pd.read_csv(
filepath_or_buffer="http://lib.stat.cmu.edu/datasets/boston",
delim_whitespace=True,
skiprows=21,
header=None,
)
columns = [
'CRIM',
'ZN',
'INDUS',
'CHAS',
'NOX',
'RM',
'AGE',
'DIS',
'RAD',
'TAX',
'PTRATIO',
'B',
'LSTAT',
'MEDV',
]
#Flatten all the values into a single long list and remove the nulls
values_w_nulls = df.values.flatten()
all_values = values_w_nulls[~np.isnan(values_w_nulls)]
#Reshape the values to have 14 columns and make a new df out of them
df = pd.DataFrame(
data = all_values.reshape(-1, len(columns)),
columns = columns,
)
df
CodePudding user response:
Try like it is done in the sklearn documentation:
data_url = "http://lib.stat.cmu.edu/datasets/boston"
raw_df = pd.read_csv(data_url, sep="\s ", skiprows=22, header=None)