I have the following query (automatically generated):
MATCH (dg:DecisionGroup {id: -3})-[rdgd:CONTAINS]->(childD:Vacancy ) -[:REQUIRES]->(ceNode:Requirable)
WHERE ceNode.id in [1, 2, 6, 7, 8, 9, 10]
WITH DISTINCT childD, rdgd, dg, collect(ceNode) as ceNodes
with childD, dg, rdgd,
apoc.coll.toSet(reduce(ceNodeLabels = [], n IN ceNodes | ceNodeLabels labels(n))) as ceNodeLabels
WHERE all(x IN ['Employment', 'Location'] WHERE x IN ceNodeLabels)
WITH childD
WHERE (childD.`active` = true) AND ( (childD.`salaryUsd` >= 5492) OR (childD.`hourlyRateUsd` >= 124) )
WITH childD
OPTIONAL MATCH (childD)-[vg:HAS_VOTE_ON]->(c:Criterion)
WHERE c.id IN [16, 18, 4, 21, 22, 7, 8, 9, 14]
WITH childD, vg.avgVotesWeight as weight, vg.totalVotes as totalVotes
WITH childD , toFloat(sum(weight)) as weight, toInteger(sum(totalVotes)) as totalVotes
WHERE weight > 0
WITH childD, weight, totalVotes
MATCH (dg:DecisionGroup {id: -3})-[rdgd:CONTAINS]->(childD)
OPTIONAL MATCH (childD)-[ru:CREATED_BY]->(u:User)
WITH childD, dg, rdgd, u, ru , weight, totalVotes
ORDER BY totalVotes DESC, childD.createdAt DESC
SKIP 0 LIMIT 10
RETURN childD AS decision, dg, rdgd, u, ru, weight, totalVotes,
[ (c1)<-[vg1:HAS_VOTE_ON]-(childD) | {criterion: c1, relationship: vg1} ] AS weightedCriteria ,
[ (c1t:Translation)<-[rc1t:CONTAINS]-(c1)<-[vg1:HAS_VOTE_ON]-(childD) WHERE c1t.iso6391 = 'uk' | {entityId: toInteger(c1.id), translation: c1t} ] AS weightedCriteriaTranslations ,
[ (childD)-[:REQUIRES]->(ce:CompositeEntity) | {entity: ce} ] AS decisionCompositeEntities,
[ (childD)-[:REQUIRES]->(ce:CompositeEntity)-[:CONTAINS]->(trans:Translation) WHERE trans.iso6391 = 'uk' | {entityId: toInteger(id(ce)), translation: trans} ] AS decisionCompositeEntitiesTranslations,
[ (childD)-[:CONTAINS]->(trans:Translation) WHERE trans.iso6391 = 'uk' | {entityId: toInteger(childD.id), translation: trans} ] AS decisionTranslations
Right now query takes ~2 sec to complete on 10k childD nodes
Is there something I may refactor in the query in order to improve the execution time?
This is an execution plan:
Cypher version: CYPHER 4.4, planner: COST, runtime: INTERPRETED. 2929280 total db hits in 1908 ms
SVG version: 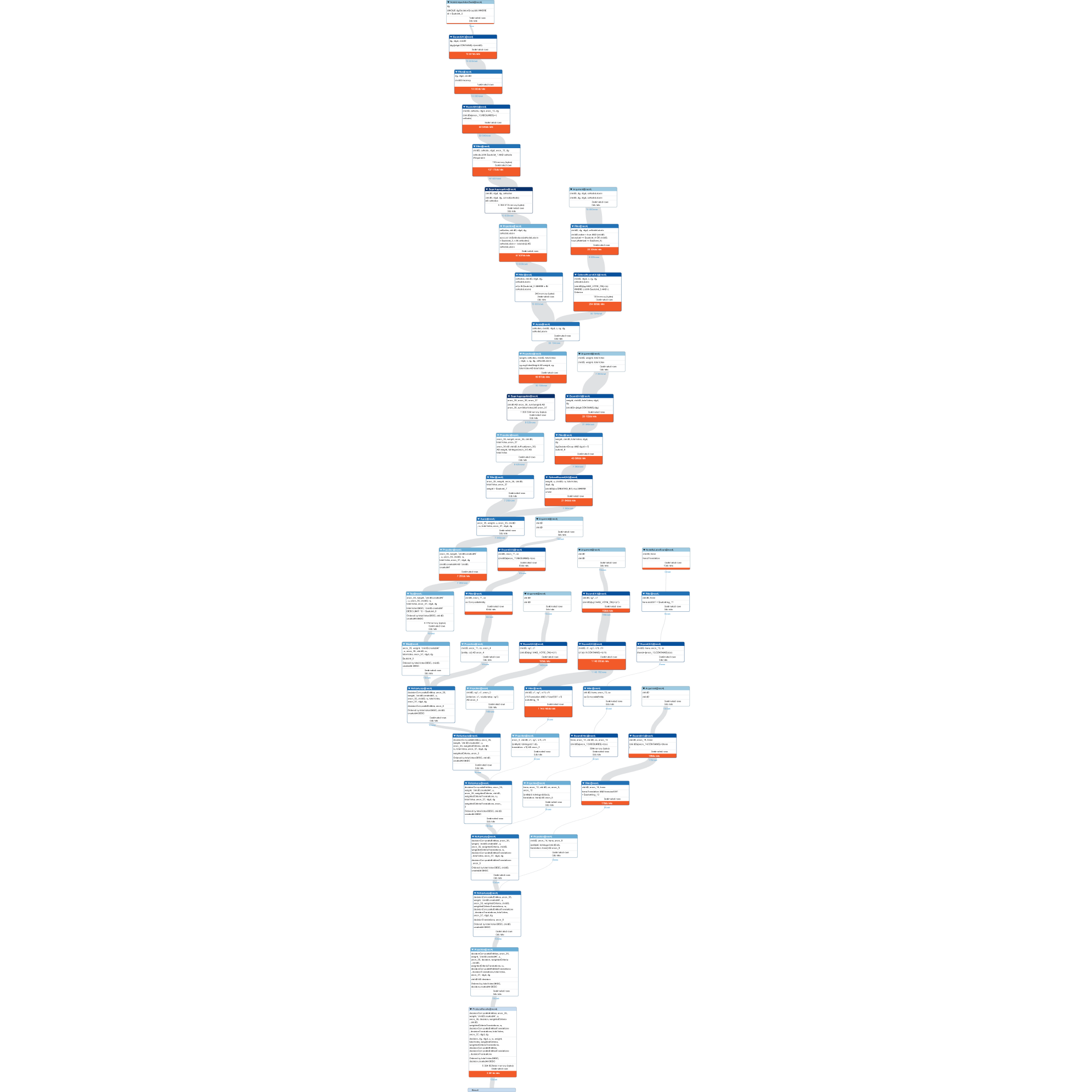
CodePudding user response:
Some thoughts when looking at your query:
if the collections of nodeIds , like in
WHERE ceNode.id in [1, 2, 6, 7, 8, 9, 10]
are also part of the dynamically created cypher, you may consider using parameters. In that case, Neo4j does not have to create a new query plan every time.
in this part
WITH DISTINCT childD, rdgd, dg, collect(ceNode) as ceNodes
you do not need the DISTINCT because that happens automatically since you have the COLLECT()
CodePudding user response:
I see that line 16 has 1.1M db hits in the query execution plan and it is a duplication of line 1.
line 01: MATCH (dg:DecisionGroup {id: -3})-[rdgd:CONTAINS]->(childD:Vacancy ) -[:REQUIRES]->(ceNode:Requirable)
line 16: MATCH (dg:DecisionGroup {id: -3})-[rdgd:CONTAINS]->(childD)
It is not needed because the childD that you get from line 1 will be the same with line 16 and it is contained by the same DecisionGroup with id=-3. Try removing it and see if the result is the same as before.
MATCH (dg:DecisionGroup {id: -3})-[rdgd:CONTAINS]->(childD:Vacancy ) -[:REQUIRES]->(ceNode:Requirable)
WHERE ceNode.id in [1, 2, 6, 7, 8, 9, 10]
WITH DISTINCT childD, rdgd, dg, collect(ceNode) as ceNodes
with childD, dg, rdgd,
apoc.coll.toSet(reduce(ceNodeLabels = [], n IN ceNodes | ceNodeLabels labels(n))) as ceNodeLabels
WHERE all(x IN ['Employment', 'Location'] WHERE x IN ceNodeLabels)
WITH childD, dg, rdgd
WHERE (childD.`active` = true) AND ( (childD.`salaryUsd` >= 5492) OR (childD.`hourlyRateUsd` >= 124) )
WITH childD, dg, rdgd
OPTIONAL MATCH (childD)-[vg:HAS_VOTE_ON]->(c:Criterion)
WHERE c.id IN [16, 18, 4, 21, 22, 7, 8, 9, 14]
WITH childD, dg, rdgd, vg.avgVotesWeight as weight, vg.totalVotes as totalVotes
WITH childD, dg, rdgd, toFloat(sum(weight)) as weight, toInteger(sum(totalVotes)) as totalVotes
WHERE weight > 0
WITH childD, dg, rdgd, weight, totalVotes
OPTIONAL MATCH (childD)-[ru:CREATED_BY]->(u:User)
WITH childD, dg, rdgd, u, ru , weight, totalVotes
ORDER BY totalVotes DESC, childD.createdAt DESC
SKIP 0 LIMIT 10
RETURN childD AS decision, dg, rdgd, u, ru, weight, totalVotes,
[ (c1)<-[vg1:HAS_VOTE_ON]-(childD) | {criterion: c1, relationship: vg1} ] AS weightedCriteria ,
[ (c1t:Translation)<-[rc1t:CONTAINS]-(c1)<-[vg1:HAS_VOTE_ON]-(childD) WHERE c1t.iso6391 = 'uk' | {entityId: toInteger(c1.id), translation: c1t} ] AS weightedCriteriaTranslations ,
[ (childD)-[:REQUIRES]->(ce:CompositeEntity) | {entity: ce} ] AS decisionCompositeEntities,
[ (childD)-[:REQUIRES]->(ce:CompositeEntity)-[:CONTAINS]->(trans:Translation) WHERE trans.iso6391 = 'uk' | {entityId: toInteger(id(ce)), translation: trans} ] AS decisionCompositeEntitiesTranslations,
[ (childD)-[:CONTAINS]->(trans:Translation) WHERE trans.iso6391 = 'uk' | {entityId: toInteger(childD.id), translation: trans} ] AS decisionTranslations