I have a piece of code which generates a list of nested dictionaries like below:
[{'cb': ({'Name': 'A', 'ID': 1, 'num': 50},
{'Name': 'A', 'ID': 2, 'num': 68}),
'final_value': 118},
{'cb': ({'Name': 'A', 'ID': 1, 'num': 50},
{'Name': 'A', 'ID': 4, 'num': 67}),
'final_value': 117},
{'cb': ({'Name': 'A', 'ID': 1, 'num': 50},
{'Name': 'A', 'ID': 6, 'num': 67}),
'final_value': 117}]
I want to convert the dictionary into a dataframe like below
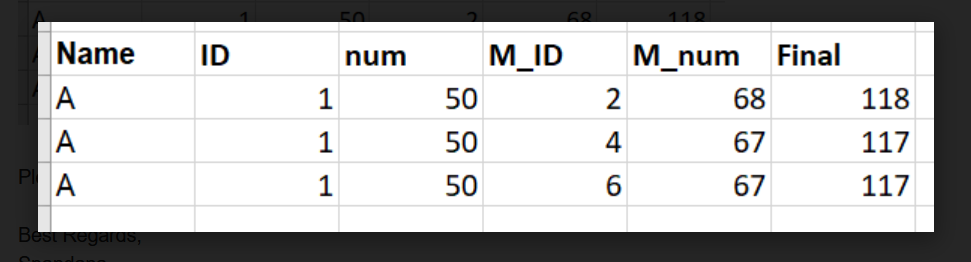
How can I do it using Python?
I have tried the below piece of code
merge_values = [{'cb': ({'Name': 'A', 'ID': 1, 'num': 50},
{'Name': 'A', 'ID': 2, 'num': 68}),
'final_value': 118},
{'cb': ({'Name': 'A', 'ID': 1, 'num': 50},
{'Name': 'A', 'ID': 4, 'num': 67}),
'final_value': 117},
{'cb': ({'Name': 'A', 'ID': 1, 'num': 50},
{'Name': 'A', 'ID': 6, 'num': 67}),
'final_value': 117}]
test = pd.DataFrame()
i = 0
for match in merge_values:
for d in match:
final_cfr = d['final_value']
comb = d['cb']
i = i 1
z = pd.DataFrame()
for t in comb:
dct = {k:[v] for k,v in t.items()}
x = pd.DataFrame(dct)
x['merge_id'] = i
x['Final_Value'] = final_value
test = pd.concat([test, x])
The problem with this piece of code is it adds the rows one below another. I need the elements of the tuple next to each other.
CodePudding user response:
You will need to clean your data by creating a new dict with the structure that you want, like this:
import pandas as pd
dirty_data = [{'cb': ({'Name': 'A', 'ID': 1, 'num': 50},
{'Name': 'A', 'ID': 2, 'num': 68}),
'final_value': 118},
{'cb': ({'Name': 'A', 'ID': 1, 'num': 50},
{'Name': 'A', 'ID': 4, 'num': 67}),
'final_value': 117},
{'cb': ({'Name': 'A', 'ID': 1, 'num': 50},
{'Name': 'A', 'ID': 6, 'num': 67}),
'final_value': 117}]
def clean_data(dirty_data: dict) -> dict:
names = []
ids = []
nums = []
m_ids = []
m_nums = []
finals = []
for cb in dirty_data:
names.append(cb["cb"][0]["Name"])
ids.append(cb["cb"][0]["ID"])
nums.append(cb["cb"][0]["num"])
m_ids.append(cb["cb"][1]["ID"])
m_nums.append(cb["cb"][1]["num"])
finals.append(cb["final_value"])
return {"Name": names, "ID": ids, "num": nums, "M_ID": m_ids, "M_num": m_nums, "Final": finals}
df = pd.DataFrame(clean_data(dirty_data))
df
CodePudding user response:
You could try to read the data into a dataframe as is and then restructure it until you get the desired result, but in this case, it doesn't seem practical.
Instead, I'd flatten the input into a list of lists to pass to pd.DataFrame. Here is a relatively concise way to do that with your sample data:
from operator import itemgetter
import pandas as pd
data = [{'cb': ({'Name': 'A', 'ID': 1, 'num': 50},
{'Name': 'A', 'ID': 2, 'num': 68}),
'final_value': 118},
{'cb': ({'Name': 'A', 'ID': 1, 'num': 50},
{'Name': 'A', 'ID': 4, 'num': 67}),
'final_value': 117},
{'cb': ({'Name': 'A', 'ID': 1, 'num': 50},
{'Name': 'A', 'ID': 6, 'num': 67}),
'final_value': 117}]
keys = ['Name', 'ID', 'num', 'M_Name', 'M_ID', 'M_num', 'final_value']
# generates ['A', 1, 50, 'A', 2, 68, 118] etc.
flattened = ([value for item in row['cb']
for value in itemgetter(*keys[:3])(item)]
[row['final_value']]
for row in data)
df = pd.DataFrame(flattened)
df.columns = keys
# get rid of superfluous M_Name column
df.drop('M_Name', axis=1, inplace=True)
itemgetter(*keys[:3])(item) is the same as [item[k] for k in keys[:3]]. On flattening lists of lists with list (or generator) comprehensions, see How do I make a flat list out of a list of lists?.
Result:
Name ID num M_ID M_num final_value
0 A 1 50 2 68 118
1 A 1 50 4 67 117
2 A 1 50 6 67 117