I have a large dataframe which is in long format and can be created below:
import pandas as pd
df = pd.DataFrame({'period':['2021-01-01','2021-02-01','2021-03-01','2021-03-01','2021-04-01','2021-04-01'],
'indi':['pop','vacced','tot_num_cases','tot_num_cases','pop','pop'],
'value':[10000,200,8999,8999,27000,27000]})
I want to drop duplicate rows based on the condition below:
df[df['indi'] == 'tot_num_cases'].drop_duplicates(keep="last")
but only on the rows which match the condition. How do that without dropping all duplicate rows of the dataframe. Result would look like:
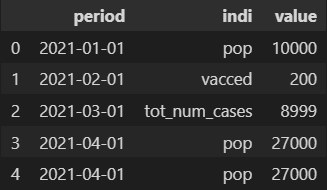
CodePudding user response:
Split the condition to two conditions, duplicate value in indi column and the value is 'tot_num_cases'
df = df[~(df.duplicated(subset='indi', keep='last') & df['indi'].eq('tot_num_cases'))]
print(df)
Output
period indi value
0 2021-01-01 pop 10000
1 2021-02-01 vacced 200
3 2021-03-01 tot_num_cases 8999
4 2021-04-01 pop 27000
5 2021-04-01 pop 27000
CodePudding user response:
You can select tot_num_cases, drop duplicates and concat with the other rows:
import pandas as pd
df = pd.DataFrame({'period':['2021-01-01','2021-02-01','2021-03-01','2021-03-01','2021-04-01','2021-04-01'],
'indi':['pop','vacced','tot_num_cases','tot_num_cases','pop','pop'],
'value':[10000,200,8999,8999,27000,27000]})
# period indi value
# 0 2021-01-01 pop 10000
# 1 2021-02-01 vacced 200
# 2 2021-03-01 tot_num_cases 8999
# 3 2021-03-01 tot_num_cases 8999
# 4 2021-04-01 pop 27000
# 5 2021-04-01 pop 27000
df = pd.concat([df.loc[df['indi']=='tot_num_cases'].drop_duplicates(keep="last"),
df.loc[df['indi']!='tot_num_cases']])
# period indi value
# 3 2021-03-01 tot_num_cases 8999
# 0 2021-01-01 pop 10000
# 1 2021-02-01 vacced 200
# 4 2021-04-01 pop 27000
# 5 2021-04-01 pop 27000