 I have a df as follows:
I have a df as follows:
import pandas as pd
import numpy as np
np.random.seed(5)
df = pd.DataFrame(np.random.randint(10, size = (20, 1)),columns=['A'])
s = [0,0,1,0,0,0,2,0,1,2,0,0,1,0,0,2,0,1,0,0]
df['B'] = s
>>> print(df)
A B
0 4 0
1 1 0
2 6 1
3 3 0
4 4 0
5 3 0
6 1 2
7 4 0
8 2 1
9 3 2
10 4 0
11 9 0
12 4 1
13 0 0
14 6 0
15 6 2
16 9 0
17 2 1
18 9 0
19 3 0
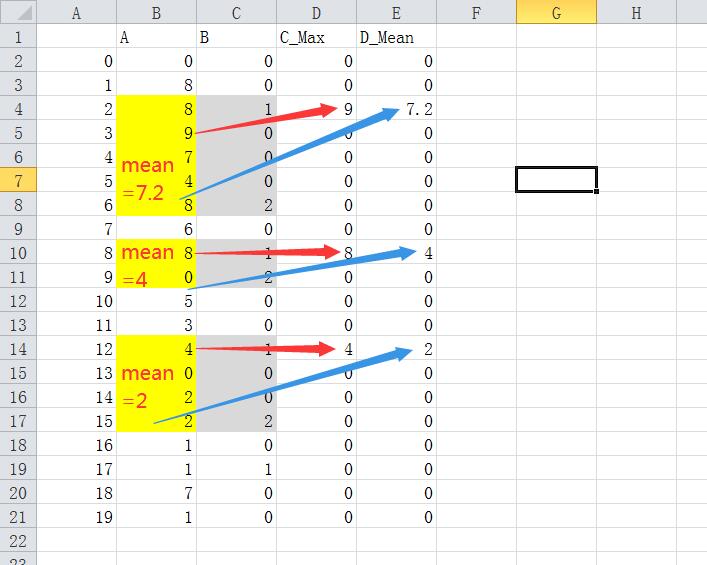
My goal is add two new columns, namely 'C_Max' and 'D_Mean'.
If the value of column B is 1, then the index from ‘1’ to the next occurrence of ‘2’ is [2:6], put the maximum value between [2:6] in column A into column C_Max at the same position with B1's 1, i.e. [2] in column C_Max, then average all the numbers [2:6] in column A, and put the result in the same position as column B in column D_Mean, that is, [2] in column D_mean. And so on.
Ignored if 2 does not appear after 1.The values of other cells in columns C_Max and D_min do not matter.
Desired output:
>>> df
A B C_Max D_Mean
0 4 0 NaN NaN
1 1 0 NaN NaN
2 6 1 6.0 3.4
3 3 0 NaN NaN
4 4 0 NaN NaN
5 3 0 NaN NaN
6 1 2 NaN NaN
7 4 0 NaN NaN
8 2 1 3.0 2.5
9 3 2 NaN NaN
10 4 0 NaN NaN
11 9 0 NaN NaN
12 4 1 6.0 4.0
13 0 0 NaN NaN
14 6 0 NaN NaN
15 6 2 NaN NaN
16 9 0 NaN NaN
17 2 1 NaN NaN
18 9 0 NaN NaN
19 3 0 NaN NaN
CodePudding user response:
The approach I took was to groupby beginnings and ends of the range - ie B equals 1 or 2. This actually created too many groups, since there are ranges in between groups, so we find the places where B = 2 (end of a streak), and take the values from there. Then we insert them at the beginnings of streaks (where B = 1).
Since there is an extra "streak beginning" (B = 1) without an end, we calculate this and pad with zero.
Hope this is clear:
df_['C_Max'] = np.nan
df_['D_Mean'] = np.nan
mask = np.cumsum(df_.B.eq(1)) np.cumsum(df_.B.eq(2)).shift()
maxes = df_.groupby(mask)['A'].cummax()
means = df_.groupby(mask)['A'].transform('mean')
streak_ends = df_.iloc[np.where(df_.B.eq(2))[0]].index
to_pad = df_.B.eq(1).sum() - df_.B.eq(2).sum()
df_.loc[df_['B'].eq(1), 'C_Max'] = maxes.loc[streak_ends].to_list() to_pad * [0]
df_.loc[df_['B'].eq(1), 'D_Mean'] = means.loc[streak_ends].to_list() to_pad * [0]
CodePudding user response:
You can achieve that with agg and merge.
Setup:
import pandas as pd
df = pd.DataFrame({'A': [4, 1, 6, 3, 4, 3, 1, 4, 2, 3, 4, 9, 4, 0, 6, 6, 9, 2, 9, 3],
'B': [0, 0, 1, 0, 0, 0, 2, 0, 1, 2, 0, 0, 1, 0, 0, 2, 0, 1, 0, 0]
})
B_groups = (df.B.eq(1) | df.B.shift().eq(2)).cumsum()
funcs = ["max", "mean"]
Merge the grouped and aggregated data with the original dataframe.
(Note how this is very maintainable – if you need additional metrics, just amend the funcs list.)
df2 = df.merge(
df.groupby(B_groups).A.agg(funcs),
left_on=B_groups,
right_index=True,
).drop("key_0", axis=1) # drop new column introduced by merge
And that is basically it. You get:
>>> df2.head(10)
A B max mean
0 4 0 4 2.5
1 1 0 4 2.5
2 6 1 6 3.4
3 3 0 6 3.4
4 4 0 6 3.4
5 3 0 6 3.4
6 1 2 6 3.4
7 4 0 4 4.0
8 2 1 3 2.5
9 3 2 3 2.5
To get rid of the superfluous values, you can re-assign the two new columns, keeping everything up to the last
non-zero value in B.
df2 = df2.loc[:df2.B[::-1].idxmax()]
df2[funcs] = df2.loc[df2.B.eq(1), funcs]
Final result:
A B max mean
0 4 0 NaN NaN
1 1 0 NaN NaN
2 6 1 6.0 3.4
3 3 0 NaN NaN
4 4 0 NaN NaN
5 3 0 NaN NaN
6 1 2 NaN NaN
7 4 0 NaN NaN
8 2 1 3.0 2.5
9 3 2 NaN NaN
10 4 0 NaN NaN
11 9 0 NaN NaN
12 4 1 6.0 4.0
13 0 0 NaN NaN
14 6 0 NaN NaN
15 6 2 NaN NaN