I´m trying to apply the following rules (picture attached) into the following dataframe (code attached).
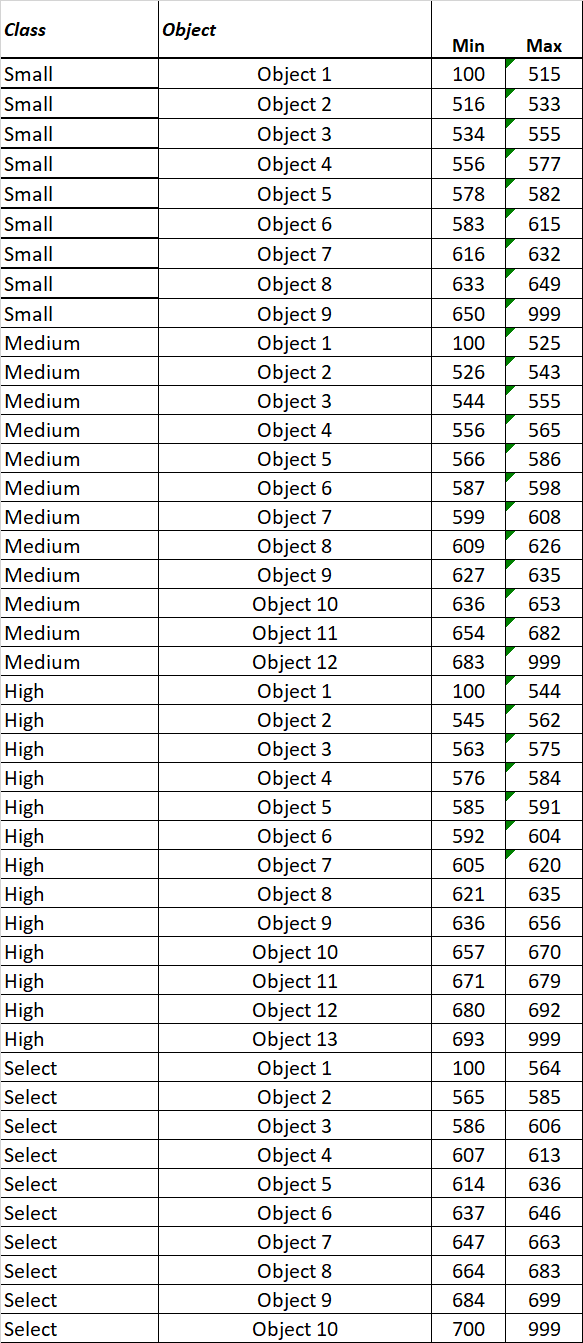
data = pd.DataFrame({'col1': [0, 700, 708, 634, 656, 663, 0, 0, 637, 700, 700, 672, 675, 580, 0, 554, 690, 624, 596, 625, 621, 606, 618, 555, 691, 539, 548, 627, 703, 701, 636, 561, 658, 0, 0, 670, 700, 0, 613, 639, 708, 691, 0, 628,
],
'col2': ['SMALL', 'HIGH', 'SELECT', 'MEDIUM', 'SELECT', 'SELECT', 'SMALL', 'HIGH', 'HIGH', 'HIGH', 'SELECT', 'SELECT', 'HIGH', 'HIGH', 'HIGH', 'MEDIUM', 'SELECT', 'SELECT', 'SELECT', 'MEDIUM', 'HIGH', 'MEDIUM', 'MEDIUM', 'HIGH', 'MEDIUM', 'HIGH', 'MEDIUM', 'HIGH', 'SELECT', 'SELECT', 'HIGH', 'MEDIUM', 'SELECT', 'SMALL', 'SMALL', 'SELECT', 'SELECT', 'MEDIUM', 'MEDIUM', 'HIGH', 'SELECT', 'HIGH', 'HIGH', 'SELECT',
]})
A possible way to insert the rules is creating a new column and charge the condition using np.select statement.
Is it possible to create a def function that don´t be so time-consuming instead of this method? Every help is welcome. Thanks
data['object'] = np.select(
[(data['col2'] == 'SMALL') & (data['col1'] >= 100) & (data['col1'] <= 515),
(data['col2'] == 'SMALL') & (data['col1'] >= 516) & (data['col1'] <= 533),
(data['col2'] == 'SMALL') & (data['col1'] >= 534) & (data['col1'] <= 555),
(data['col2'] == 'SMALL') & (data['col1'] >= 556) & (data['col1'] <= 577),
(data['col2'] == 'SMALL') & (data['col1'] >= 578) & (data['col1'] <= 582),
(data['col2'] == 'SMALL') & (data['col1'] >= 583) & (data['col1'] <= 615),
(data['col2'] == 'SMALL') & (data['col1'] >= 616) & (data['col1'] <= 632),
(data['col2'] == 'SMALL') & (data['col1'] >= 633) & (data['col1'] <= 649),
(data['col2'] == 'SMALL') & (data['col1'] >= 650) & (data['col1'] <= 999),
(data['col2'] == 'MEDIUM') & (data['col1'] >= 100) & (data['col1'] <= 525),
(data['col2'] == 'MEDIUM') & (data['col1'] >= 526) & (data['col1'] <= 543),
(data['col2'] == 'MEDIUM') & (data['col1'] >= 544) & (data['col1'] <= 555),
(data['col2'] == 'MEDIUM') & (data['col1'] >= 556) & (data['col1'] <= 565),
(data['col2'] == 'MEDIUM') & (data['col1'] >= 566) & (data['col1'] <= 586),
(data['col2'] == 'MEDIUM') & (data['col1'] >= 587) & (data['col1'] <= 598),
(data['col2'] == 'MEDIUM') & (data['col1'] >= 599) & (data['col1'] <= 608),
(data['col2'] == 'MEDIUM') & (data['col1'] >= 609) & (data['col1'] <= 626),
(data['col2'] == 'MEDIUM') & (data['col1'] >= 627) & (data['col1'] <= 635),
(data['col2'] == 'MEDIUM') & (data['col1'] >= 636) & (data['col1'] <= 653),
(data['col2'] == 'MEDIUM') & (data['col1'] >= 654) & (data['col1'] <= 682),
(data['col2'] == 'MEDIUM') & (data['col1'] >= 683) & (data['col1'] <= 999),
(data['col2'] == 'HIGH') & (data['col1'] >= 100) & (data['col1'] <= 544),
(data['col2'] == 'HIGH') & (data['col1'] >= 545) & (data['col1'] <= 562),
(data['col2'] == 'HIGH') & (data['col1'] >= 563) & (data['col1'] <= 575),
(data['col2'] == 'HIGH') & (data['col1'] >= 576) & (data['col1'] <= 584),
(data['col2'] == 'HIGH') & (data['col1'] >= 585) & (data['col1'] <= 591),
(data['col2'] == 'HIGH') & (data['col1'] >= 592) & (data['col1'] <= 604),
(data['col2'] == 'HIGH') & (data['col1'] >= 605) & (data['col1'] <= 620),
(data['col2'] == 'HIGH') & (data['col1'] >= 621) & (data['col1'] <= 635),
(data['col2'] == 'HIGH') & (data['col1'] >= 636) & (data['col1'] <= 656),
(data['col2'] == 'HIGH') & (data['col1'] >= 657) & (data['col1'] <= 670),
(data['col2'] == 'HIGH') & (data['col1'] >= 671) & (data['col1'] <= 679),
(data['col2'] == 'HIGH') & (data['col1'] >= 680) & (data['col1'] <= 692),
(data['col2'] == 'HIGH') & (data['col1'] >= 693) & (data['col1'] <= 999),
(data['col2'] == 'SELECT') & (data['col1'] >= 100) & (data['col1'] <= 564),
(data['col2'] == 'SELECT') & (data['col1'] >= 565) & (data['col1'] <= 585),
(data['col2'] == 'SELECT') & (data['col1'] >= 586) & (data['col1'] <= 606),
(data['col2'] == 'SELECT') & (data['col1'] >= 607) & (data['col1'] <= 613),
(data['col2'] == 'SELECT') & (data['col1'] >= 614) & (data['col1'] <= 636),
(data['col2'] == 'SELECT') & (data['col1'] >= 637) & (data['col1'] <= 646),
(data['col2'] == 'SELECT') & (data['col1'] >= 647) & (data['col1'] <= 663),
(data['col2'] == 'SELECT') & (data['col1'] >= 664) & (data['col1'] <= 683),
(data['col2'] == 'SELECT') & (data['col1'] >= 684) & (data['col1'] <= 699),
(data['col2'] == 'SELECT') & (data['col1'] >= 700) & (data['col1'] <= 999)
],
['Object 1', 'Object 2', 'Object 3', 'Object 4', 'Object 5', 'Object 6', 'Object 7', 'Object 8', 'Object 9',
'Object 1', 'Object 2', 'Object 3', 'Object 4', 'Object 5', 'Object 6', 'Object 7', 'Object 8', 'Object 9', 'Object 10', 'Object 11', 'Object 12',
'Object 1', 'Object 2', 'Object 3', 'Object 4', 'Object 5', 'Object 6', 'Object 7', 'Object 8', 'Object 9', 'Object 10', 'Object 11', 'Object 12', 'Object 13',
'Object 1', 'Object 2', 'Object 3', 'Object 4', 'Object 5', 'Object 6', 'Object 7', 'Object 8', 'Object 9', 'Object 10',
])
CodePudding user response:
Use groupby and cut:
bins = {'SMALL': [100, 515, 533, ... ,999],
'MEDIUM': [100, 525, 543, ... ,999],
'HIGH': [100, 544, 562, ... ,999],
'SELECT': [100, 564, 585, ... ,999]
}
labels = ['object 1', 'object 2', 'object 3', ..., 'object 13']
data['new'] = data.groupby('col2')['col1'].transform(lambda g: pd.cut(g, bins=bins[g.name], labels=labels[:len(bins[g.name])-1]))
NB. You can also use a dictionary to define different conditions for each group (labels = {'SMALL': ['A', 'B'...], 'MEDIUM': ['X', 'Y'...]...}). Then use labels=labels[g.name].
Example dummy output (I didn't use all bins):
col1 col2 new
0 0 SMALL NaN
1 700 HIGH object 3
2 708 SELECT object 3
3 634 MEDIUM object 3
4 656 SELECT object 3
5 663 SELECT object 3
6 0 SMALL NaN
7 0 HIGH NaN
8 637 HIGH object 3
...