how to apply the indicated modification process to each of the substrings extracted from the string called input_text with re.group() method, and then replace them in the original string input_text.
I think I should put a for loop that iterates over the lists inside the list called civil_time_unit_list
import re
def numerical_time_corrector(input_text):
hh, mm, am_pm, output = "", "", "", ""
input_text = re.sub(r"([0-9])h.s.", r"\1 ", input_text)
input_text = re.sub(r"([0-9])\s*h.s.", r"\1 ", input_text)
input_text = re.sub(r"([0-9])hs", r"\1 ", input_text)
input_text = re.sub(r"([0-9])\s*hs", r"\1 ", input_text)
civil_time_pattern = r'(\d{1,2})[\s|:]*(\d{0,2})\s*(am|pm)?'
civil_time_unit_list = re.findall(civil_time_pattern, input_text)
print(civil_time_unit_list)
# civil_time_unit_list[list of detected schedules][lists with the 3 elements of each of the schedules]
#process to be applied to all times detected within the input string and stored in the list
#-----------------------------------------
try:
hh = civil_time_unit_list[0][0]
if (hh == ""): hh = "00"
except IndexError: hh = "00"
try:
mm = civil_time_unit_list[0][1]
if (mm == ""): mm = "00"
except IndexError: mm = "00"
try:
am_pm = civil_time_unit_list[0][2]
if (am_pm == ""): am_pm = "am"
except IndexError: am_pm = "am"
if (len(hh) < 2):
hh = "0" hh
if (len(mm) < 2):
mm = "0" mm
output = (hh ":" mm " " am_pm).strip()
#-----------------------------------------
#Here the program should replace this new value in the original input string
#input_text = ""
#return input_text #It should return the new input_string with all values replaced
return output #I am returning the output just to test that it works, since it should return the original string but with the replacements already done.
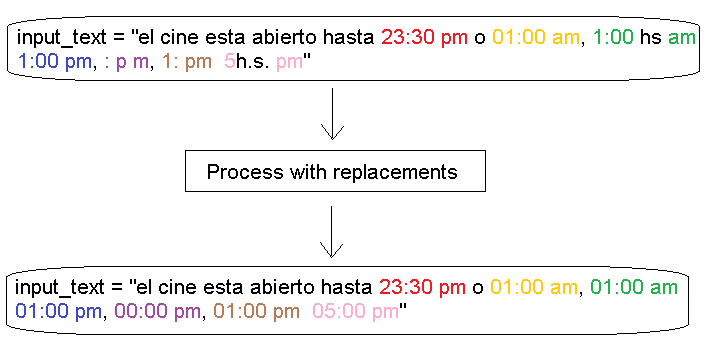
input_text = "el cine esta abierto hasta 23:30 pm o 01:00 am, 1:00 hs am 1:00 pm, : p m, 1: pm 5: h.s. pm"
input_text = numerical_time_corrector(input_text)
print(repr(input_text))
You can see how it erroneously prints only one of the values to be corrected in the original string, and not the original string with all its corrected values. This is the wrong output:
[('23', '30', 'pm'), ('01', '00', 'am'), ('1', '00', 'am'), ('1', '00', 'pm'), ('1', '', 'pm'), ('5', '', 'pm')]
'23:30 pm'
And this is the output I really need to get :
[('23', '30', 'pm'), ('01', '00', 'am'), ('1', '00', 'am'), ('1', '00', 'pm'), ('1', '', 'pm'), ('5', '', 'pm')]
'el cine esta abierto hasta 23:30 pm o 01:00 am, 01:00 am 01:00 pm, 00:00 pm, 01:00 pm 05:00 pm'
What should I change in my code so that this fix is applied to all the extracted substrings and then replace everything in input_text string and then return it from the function and print it to the console?
CodePudding user response:
Try:
import re
def numerical_time_corrector(input_text):
civil_time_pattern = r"(\d*):(\d*)\s*(?:h[ .]?s[ .]?)?\s*(a\s*m|p\s*m)?"
return re.sub(
civil_time_pattern,
lambda g: "{:>02}:{:>02} {}".format(
g[1] or "", g[2] or "", (g[3] or "").replace(" ", "")
),
input_text,
)
input_text = "el cine esta abierto hasta 23:30 pm o 01:00 am, 1:00 hs am 1:00 pm, : p m, 1: pm 5: h.s. pm"
input_text = numerical_time_corrector(input_text)
print(repr(input_text))
Prints:
'el cine esta abierto hasta 23:30 pm o 01:00 am, 01:00 am 01:00 pm, 00:00 pm, 01:00 pm 05:00 pm'
CodePudding user response:
Well, you could do this in a two step re.sub() using PyPi's regex module. For example:
import regex as re
input_text = 'el cine esta abierto hasta 23:30 pm o 01:00 am, 1:00 hs am 1:00 pm, : p m, 1: pm 5: h.s. pm'
output_text = re.sub(r'(?:(?<!\d)(?=\d?:)|(?<!\d)(:)|(?<=:)(?!\d)|(?<=:\d?)(\D))', r'0\1\2', input_text)
output_text = re.sub(r'(\d\d:\d\d)(?:\s*h\.?s\.?)?(\s[ap])\h*(m)', r'\1\2\3', output_text)
print(output_text)
Prints:
el cine esta abierto hasta 23:30 pm o 01:00 am, 01:00 am 01:00 pm, 00:00 pm, 01:00 pm 05:00 pm