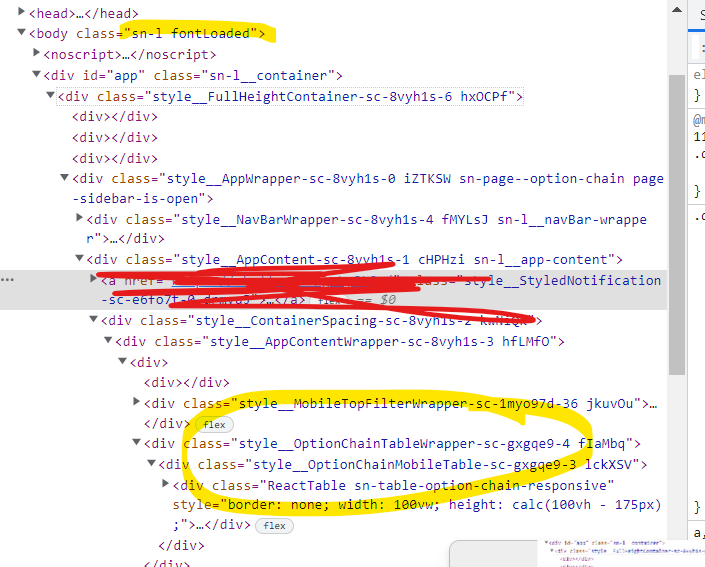
Am trying to scrape a table from a website, however am not sure if am able to correctly refer to the appropriate class. Am attaching the screenshot and also the body extracted from BeautifulSoup. Am i look at this wrongly, please excuse me, am very new to web scraping.
I need to extract the table that is present in the circled highlight, however not sure to how to traverse there.
CodePudding user response:
The webpage is loaded by JavaScript. So you can use selenium with bs4.
An example with working solution:
import pandas as pd
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
import time
from selenium.webdriver.chrome.options import Options
webdriver_service = Service("./chromedriver") #Your chromedriver path
driver = webdriver.Chrome(service=webdriver_service)
url = 'https://web.sensibull.com/option-chain?expiry=2022-08-25&tradingsymbol=NIFTY'
driver.get(url)
driver.maximize_window()
time.sleep(8)
soup=BeautifulSoup(driver.page_source, 'lxml')
data = []
for row in soup.find_all('div',class_="rt-tr-group"):
OI_change = row.select_one('div.rt-td:nth-child(1)').text
OI_lakh = row.select_one('div.rt-td:nth-child(2)').text
LTP = row.select_one('div.rt-td:nth-child(3)').get_text(strip=True)
data.append({
'OI_change':OI_change,
'OI_lakh':OI_lakh,
'LTP':LTP
})
df = pd.DataFrame(data)
print(df)
Output:
OI_change OI_lakh LTP
0 - 0.1 1354.200%
1 -7.0% 1.4 1429.20 11%
2 - 0.2 1354.65 8%
3 -3.3% 0.8 1332.75 11%
4 -25.0% 0.0 1109.80-4%
.. ... ... ...
56 -21.2% 1.1 0.85-62%
57 -2.3% 59.5 0.95-58%
58 -10.9% 0.6 0.75-63%
59 -33.2% 6.2 0.65-70%
60 -26.1% 0.3 0.60-71%
[61 rows x 3 columns]