So, my code looks like this:
from bs4 import BeautifulSoup
import requests
from selenium import webdriver
import time
from selenium.webdriver.common.keys import Keys
from selenium.webdriver import ActionChains
from selenium.webdriver.common.keys import Keys
import pyautogui
from selenium.webdriver.support.ui import WebDriverWait
keyword='milk'
browser = webdriver.Edge(r"C:\Users\solan\Documents\edgedriver_win32\msedgedriver.exe")
browser.get('https://fdc.nal.usda.gov/fdc-app.html#/?query=' keyword '')
#element1= browser.find_element_by_xpath('/html/body/div/main/app-root/app-food-search/div/div/div[1]/div[4]/table')
element1= browser.find_elements_by_xpath('//a[@]')
#data=element1.text
for item in element1:
print(item.text)
Food= input("")
time.sleep(10)
z=browser.find_element_by_link_text(Food).click()
It outputs a list, from which I select "Yogurt, plain, whole milk" and click enter. On this page there is a Table of food contents. I would like to extract the table directly into Pd dataframe or a CSV.
I am trying this to get the table contents:
for table in browser.find_elements_by_xpath('/html/body/div/main/app-root/app-food-details/div/div/div[2]/div/div/div/app-food-nutrients/div/div[2]/table'):
print(table.text)
Which outputs: Image
{kind=link}
The table.text is a str and I am not quite sure how could I fit it in a csv or df. Even if I try to fit, it just fits itself in a single row. It doesnt detect a table format. Does anyone have any suggestions?
CodePudding user response:
That table is being hydrated via an XHR network call (see Dev Tools - network tab). You can do something like this, avoiding the overheads of selenium and whatever heavy artillery you are using:
import requests
import pandas as pd
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36"
}
url = 'https://fdc.nal.usda.gov/portal-data/external/2259793'
r = requests.get(url, headers=headers)
#print(r.json())
df = pd.json_normalize(r.json()['foodNutrients'])
print(df)
This will return a dataframe (which you can further save to csv, if you want):
[...] (too big to post it here)
You can inspect further that json response, and eventually try to flatten (normalize) it, or you can select only specific columns from that dataframe. Pandas docs relevant to reading json: https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.read_json.html
CodePudding user response:
To extract the <table> data you need to induce WebDriverWait for the visibility_of_element_located() of the <table> element, extract the outerHTML, read the outerHTML using read_html() and you can use the following Locator Strategies:
Code Block:
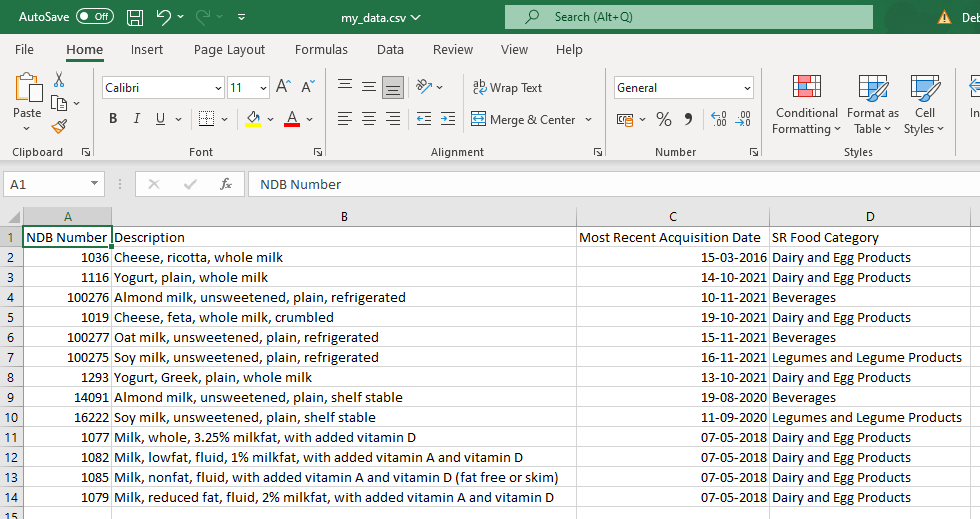
driver.get('https://fdc.nal.usda.gov/fdc-app.html#/?query=milk') time.sleep(5) data = WebDriverWait(driver, 20).until(EC.visibility_of_element_located((By.CSS_SELECTOR, "table.usa-table-results.usa-table-borderless.header-alignment"))).get_attribute("outerHTML") df = pd.read_html(data) print(df) driver.quit()Console Output:
[ NDB Number ... SR Food Category 0 1036 ... Dairy and Egg Products 1 1116 ... Dairy and Egg Products 2 100276 ... Beverages 3 1019 ... Dairy and Egg Products 4 100277 ... Beverages 5 100275 ... Legumes and Legume Products 6 1293 ... Dairy and Egg Products 7 14091 ... Beverages 8 16222 ... Legumes and Legume Products 9 1077 ... Dairy and Egg Products 10 1082 ... Dairy and Egg Products 11 1085 ... Dairy and Egg Products 12 1079 ... Dairy and Egg Products [13 rows x 4 columns]]
Now you can easily copy the data into a csv file as follows:
df[0].to_csv("my_data.csv", index=False)
Snapshot of the csv file: