This is the edited version of the question.
I need help to convert my wide data to long format data using the pivot_longer() function in R. The main problem is wanting to create long data with a variable nested in another variable.
For example, if I have wide data like this, where
- variable
fu1andfu2are variables for the follow-up (in days). There are two follow-up events (fu1andfu2) - variables
cpassandisare the results of two tests at each follow up
IDno <- c(1,2)
Sex <- c("M","F")
fu1 <- c(13,15)
fu2 <- c(20,18)
cpass1 <- c(27, 85)
cpass2 <- c(33, 90)
is1 <- c(201, 400)
is2 <- c(220, 430)
mydata <- data.frame(IDno, Sex,
fu1, cpass1, is1,
fu2, cpass2, is2)
mydata
which looks like this

And now, I want to convert it to long format data, and it should look like this:
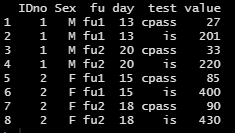
I have tried the codes below, but they do not produce the data frame in the format that I want:
#renaming variables
mydata_wide <- mydata %>%
rename(fu1_day = fu1,
cp_one = cpass1,
is_one = is1,
fu2_day = fu2,
cp_two = cpass2,
is_two = is2)
#pivoting
mydata_wide %>%
pivot_longer(
cols = c(fu1_day, fu2_day),
names_to = c("fu", ".value"),
values_to = "day",
names_sep = "_") %>%
pivot_longer(
cols = c("cp_one", "is_one", "cp_two", "is_two"),
names_to = c("test", ".value"),
values_to = "value",
names_sep = "_")
The data frame, unfortunately, looks like this:
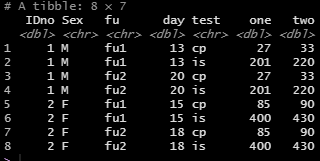
I have looked at some tutorials but have not found the best solution for this problem. Any help is very much appreciated.
CodePudding user response:
library(tidyverse)
mydata %>% # the "nested" pivoting must be done within two calls
pivot_longer(cols=c(fu1,fu2),names_to = 'fu', values_to = 'day') %>%
pivot_longer(cols=c(starts_with('cpass'), starts_with('is')),
names_to = 'test', values_to = 'value') %>%
# with this filter check not mixing the tests and the follow-ups
filter(str_extract(fu,"\\d") == str_extract(test,"\\d")) %>%
mutate(test = gsub("\\d","",test)) # remove numbers in strings
Output:
# A tibble: 8 × 6
IDno Sex fu day test value
<dbl> <chr> <chr> <dbl> <chr> <dbl>
1 1 M fu1 13 cpass 27
2 1 M fu1 13 is 201
3 1 M fu2 20 cpass 33
4 1 M fu2 20 is 220
5 2 F fu1 15 cpass 85
6 2 F fu1 15 is 400
7 2 F fu2 18 cpass 90
8 2 F fu2 18 is 430
I'm not sure if your example is your real expected output, the first dataset and the output example that you describe do not show the same information.