I have a dataframe that looks like this.
import pandas as pd
import numpy as np
# data's stored in dictionary
details = {
'address_id': [111, 111, 111, 111, 222, 222, 222, 222, 333],
'mydate':['2022-01-24', '2022-01-24', '2022-03-28', '2022-03-28', '2022-01-24', '2022-01-24', '2022-03-28', '2022-03-28', '2022-01-24'],
'mystring': ['att', 'verizon', 'comcast', 'verizon', 'att', 'verizon', 'att', 'verizon', 'verizon']
}
df = pd.DataFrame(details)
df
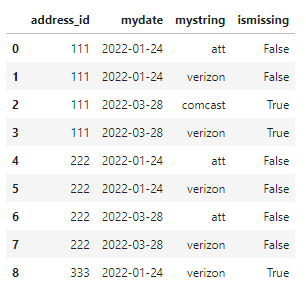
For a group of identical IDs and changing dates, I want to see if a string is NOT found. Basically, I want to see if 'att' is found in earlier dates and missing in later dates. If 'att' shows up repeatedly in earlier and later dates, I don't care.
The logic is:
att shows up in 111 & 1/24/2022 att is missing in 111 & 3/28/2022
I want to end up with a dataframe like this.
address_id mydate mystring ismissing
0 111 2022-01-24 att False
1 111 2022-01-24 verizon False
2 111 2022-03-28 comcast True
3 111 2022-03-28 verizon True
4 222 2022-01-24 att False
5 222 2022-01-24 verizon False
6 222 2022-03-28 att False
7 222 2022-03-28 verizon False
8 333 2022-01-24 verizon False
CodePudding user response:
Combine 2 boolean masks with and:
- first (
id_has_attr) tells whetherattris present for each id - second assumes it is present, and checks further conditions
id_has_attr = df.groupby('address_id')['mystring'].transform(
lambda col: col.str.contains('att').any()
)
df['ismissing'] = df.groupby(['address_id', 'mydate'])['mystring'].transform(
lambda col: ~ col.str.contains('att').any()
) & id_has_attr
Result:
address_id mydate mystring ismissing
0 111 2022-01-24 att False
1 111 2022-01-24 verizon False
2 111 2022-03-28 comcast True
3 111 2022-03-28 verizon True
4 222 2022-01-24 att False
5 222 2022-01-24 verizon False
6 222 2022-03-28 att False
7 222 2022-03-28 verizon False
8 333 2022-01-24 verizon False