I do not get all values.
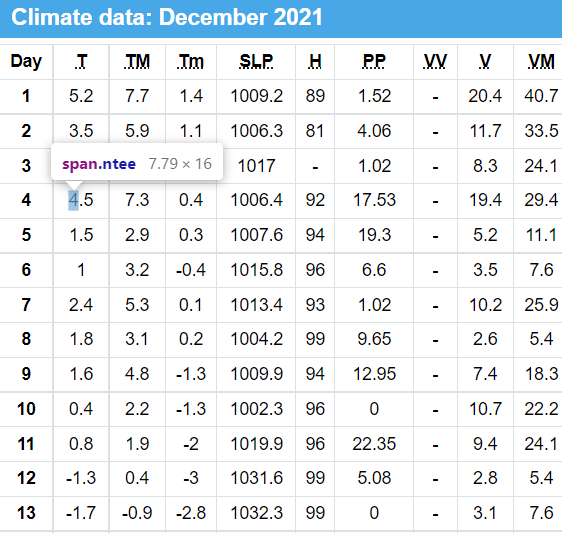
Here is what the original table looks like, here you can see at position Day4 and T there is an extra span class"ntee" which represents number 4
 Here is how I get it into pandas
Here is how I get it into pandas
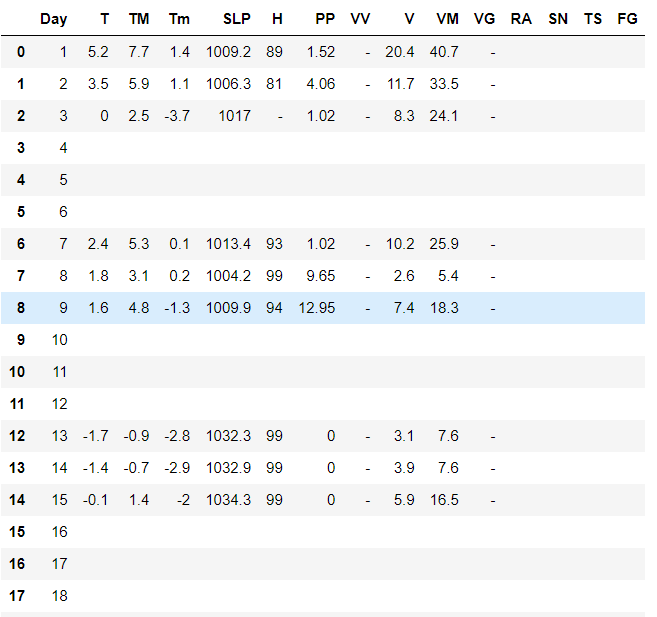
Is there a way to get all data?
from bs4 import BeautifulSoup as bs
import pandas as pd
pd.set_option('display.max_colwidth', 500)
import time
import requests
page = requests.get("https://en.tutiempo.net/climate/01-2021/ws-66320.html/")
page
soup = bs(page.content)
soup
myTable=soup.find('table',{'class':"medias mensuales numspan"})
myTable
row_headers=[]
for x in myTable.find_all("tr"):
for y in x.find_all("th"):
row_headers.append(y.text)
row_headers
table_values= []
for x in myTable.find_all("tr")[1:]:
td_tags = x.find_all("td")
td_values= [y.text for y in td_tags]
table_values.append(td_values)
table_values
pd.DataFrame(table_values[:-2],columns=row_headers[:-1])
CodePudding user response:
I will just explain the logic of work with a simple example. When you get the page, in the style tag, the page generates values corresponding to the class values of the span tag.
<style>.tablancpy{-webkit-touch-callout:none;-webkit-user-select: none;-khtml-user-select: none;-moz-user-select: none;-ms-user-select: none;user-select: none;}.numspan span.ntjk::after{content:"1";color:black;}.numspan span.ntrs::after{content:"2";color:black;}.numspan span.ntza::after{content:"3";color:black;}.numspan span.ntaa::after{content:"4";color:black;}.numspan span.ntbz::after{content:"5";color:black;}.numspan span.ntgy::after{content:"6";color:black;}.numspan span.ntox::after{content:"7";color:black;}.numspan span.ntqr::after{content:"8";color:black;}.numspan span.ntnt::after{content:"9";color:black;}.numspan span.ntbc::after{content:"0";color:black;}.numspan span.ntvr::after{content:".";color:black;}.numspan span.ntzz::after{content:"-";color:black;}</style>
If we look at the table, where there is no value, we see this
<td><span ></span><span ></span><span ></span></td>
Further, the logic is simple if there is no text in the td tag. We just take the class names of the span tag and compare them with the data obtained. Examlpe:
response = requests.get('https://en.tutiempo.net/climate/12-2021/ws-66320.html')
matches = re.findall(r'\.\w{4}::', response.text)
foo = ['1', '2', '3', '4', '5', '6', '7', '8', '9', '0', '.', '-']
spans = dict(zip([x[1:-2] for x in matches], foo))
soup = BeautifulSoup(response.text, 'lxml')
for tr in soup.find('table', class_='medias mensuales numspan').find_all('tr')[3:5]:
for td in tr.find_all('td'):
if td.get_text():
print(td.get_text())
else:
span_classes = [x.get('class')[0] for x in td.find_all('span')]
print(span_classes, ''.join([spans[x] for x in span_classes]))
OUTPUT:
3
0
2.5
-3.7
1017
-
1.02
-
8.3
24.1
-
4
['ntee', 'ntkk', 'ntgo'] 4.5
['ntpo', 'ntkk', 'ntef'] 7.3
['ntfg', 'ntkk', 'ntee'] 0.4
['ntno', 'ntfg', 'ntfg', 'ntdr', 'ntkk', 'ntee'] 1006.4
['ntjg', 'ntvw'] 92
['ntno', 'ntpo', 'ntkk', 'ntgo', 'ntef'] 17.53
['ntjj'] -
['ntno', 'ntjg', 'ntkk', 'ntee'] 19.4
['ntvw', 'ntjg', 'ntkk', 'ntee'] 29.4
['ntjj'] -
UPDATE:
page = requests.get("https://en.tutiempo.net/climate/01-2021/ws-66320.html/")
soup = bs(page.text, 'lxml')
matches = re.findall(r'\.\w{4}::', page.text)
foo = ['1', '2', '3', '4', '5', '6', '7', '8', '9', '0', '.', '-']
spans = dict(zip([x[1:-2] for x in matches], foo))
myTable = soup.find('table', {'class': "medias mensuales numspan"})
row_headers = []
for x in myTable.find_all("tr"):
for y in x.find_all("th"):
row_headers.append(y.text)
table_values = []
for x in myTable.find_all("tr")[1:]:
td_values = []
for td in x.find_all('td'):
if td.get_text():
td_values.append(td.get_text())
else:
td_values.append(''.join([spans[y] for y in [y.get('class')[0] for y in td.find_all('span')]]))
table_values.append(td_values)
df = pd.DataFrame(table_values[:-2], columns=row_headers[:-1])
print(df)
CodePudding user response:
from bs4 import BeautifulSoup as bs
import pandas as pd
pd.set_option('display.max_colwidth', 500)
import time
import requests
import re
response = requests.get('https://en.tutiempo.net/climate/12-2021/ws-66320.html')
matches = re.findall(r'\.\w{4}::', response.text)
foo = ['1', '2', '3', '4', '5', '6', '7', '8', '9', '0', '.', '-']
spans = dict(zip([x[1:-2] for x in matches], foo))
soup = bs(response.text, 'lxml')
row_headers=[]
for x in soup.find('table', class_='medias mensuales numspan').find_all('tr'):
for y in x.find_all("th"):
row_headers.append(y.text)
row_headers
table_values= []
for tr in soup.find('table', class_='medias mensuales numspan').find_all('tr')[1:]:
for td in tr.find_all('td'):
if td.get_text():
table_values.append(td.get_text())
else:
span_classes = [x.get('class')[0] for x in td.find_all('span')]
table_values.append(''.join([spans[x] for x in span_classes]))
pd.DataFrame(table_values[:-2],columns=row_headers[:-1])
Code works perfectly until I want to create the DataFrame, than I get the following error:
--------------------------------------------------------------------------- ValueError Traceback (most recent call last) ~\AppData\Local\Temp/ipykernel_24296/2958017020.py in 29 30 ---> 31 pd.DataFrame(table_values[:-2],columns=row_headers[:-1])
C:\Anaconda\lib\site-packages\pandas\core\frame.py in init(self, data, index, columns, dtype, copy) 709 ) 710 else: --> 711 mgr = ndarray_to_mgr( 712 data, 713 index,
C:\Anaconda\lib\site-packages\pandas\core\internals\construction.py in ndarray_to_mgr(values, index, columns, dtype, copy, typ) 322 ) 323 --> 324 _check_values_indices_shape_match(values, index, columns) 325 326 if typ == "array":
C:\Anaconda\lib\site-packages\pandas\core\internals\construction.py in _check_values_indices_shape_match(values, index, columns) 391 passed = values.shape 392 implied = (len(index), len(columns)) --> 393 raise ValueError(f"Shape of passed values is {passed}, indices imply {implied}") 394 395
ValueError: Shape of passed values is (478, 1), indices imply (478, 15)