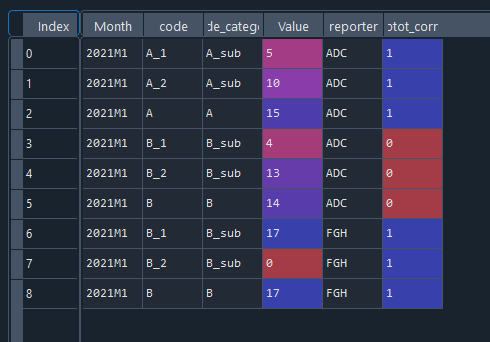
I have a dataframe with a code, its code category and their corresponding values. I would like to compare the total of a category (A, B ) with the sum of their subtotal (A_1, B_2..) and add a column to the dataframe if the values are the same then return 1 otherwise 0.
| Month | code | code_category | Value | reporter |
|---|---|---|---|---|
| 2021M1 | A_1 | A_sub | 5 | ADC |
| 2021M1 | A_2 | A_sub | 10 | ADC |
| 2021M1 | A | A | 15 | ADC |
| 2021M1 | B_1 | B_sub | 4 | ADC |
| 2021M1 | B_2 | B_sub | 13 | ADC |
| 2021M1 | B | B | 14 | ADC |
| 2021M1 | B_1 | B_sub | 17 | FGH |
| 2021M1 | B_2 | B_sub | 0 | FGH |
| 2021M1 | B | B | 17 | FGH |
The desired output should be :
| Month | code | code_category | Value | reporter | subtot_correct |
|---|---|---|---|---|---|
| 2021M1 | A_1 | A_sub | 5 | ADC | 1 |
| 2021M1 | A_2 | A_sub | 10 | ADC | 1 |
| 2021M1 | A | A | 15 | ADC | 1 |
| 2021M1 | B_1 | B_sub | 4 | ADC | 0 |
| 2021M1 | B_2 | B_sub | 13 | ADC | 0 |
| 2021M1 | B | B | 14 | ADC | 0 |
| 2021M1 | B_1 | B_sub | 17 | FGH | 1 |
| 2021M1 | B_2 | B_sub | 0 | FGH | 1 |
| 2021M1 | B | B | 17 | FGH | 1 |
I aim just to flag the pair of month, reporter and code that have not the same subtotal, so any other suggestions on the column SUBTOT_CORRECT is welcome.
CodePudding user response:
Might be a more efficent/eligant way, but this is what I came up with.
Looks like the sub-categories also invlove the 'reporter', so groupby 'code_category' and 'reporter' and sum the values. Then merge that to the dataframe.
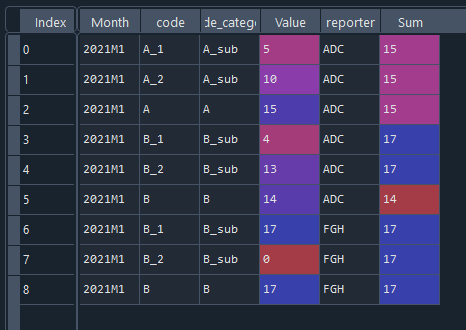
Next combine the main category and reporter to get a "key" value.
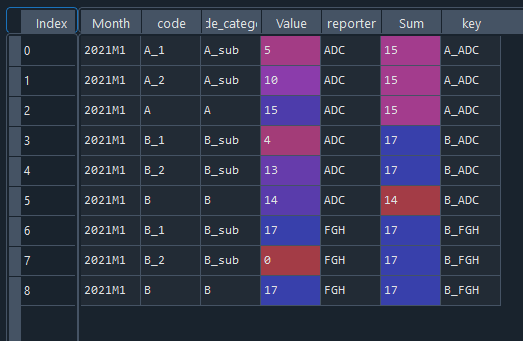
Count up the unique values within the "key" groups
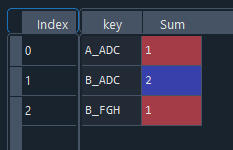
Map those values into the dataframe column
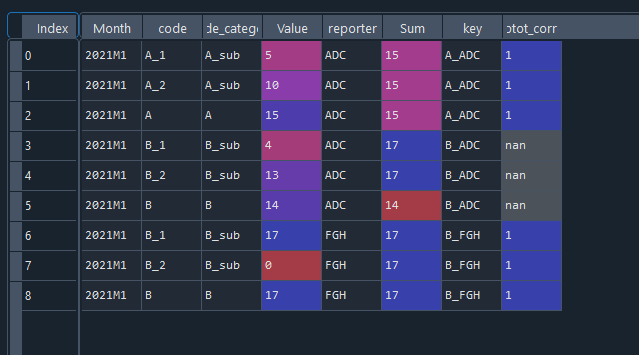
Lastly, fill with 0 where not equal to 1, and drop those columns used to merge on.
Code:
import pandas as pd
import numpy as np
cols = ['Month','code','code_category','Value','reporter']
data = [
['2021M1', 'A_1', 'A_sub', 5, 'ADC'],
['2021M1', 'A_2', 'A_sub', 10, 'ADC'],
['2021M1', 'A', 'A', 15, 'ADC'],
['2021M1', 'B_1', 'B_sub', 4, 'ADC'],
['2021M1', 'B_2', 'B_sub', 13, 'ADC'],
['2021M1', 'B', 'B', 14, 'ADC'],
['2021M1', 'B_1', 'B_sub', 17, 'FGH'],
['2021M1', 'B_2', 'B_sub', 0, 'FGH'],
['2021M1', 'B', 'B', 17, 'FGH']]
df = pd.DataFrame(data, columns=cols)
grouped = df.groupby(['code_category', 'reporter']).sum()
grouped = grouped.reset_index(drop=False)
grouped = grouped.rename(columns=({'Value':'Sum'}))
df = df.merge(grouped, how='left', left_on=['code_category', 'reporter'], right_on=['code_category', 'reporter'])
df['key'] = df['code_category'].str.replace('_sub', '') '_' df['reporter']
lenUnique = dict(df.groupby(['key'])['Sum'].nunique())
df['subtot_correct'] = df['key'].map(lenUnique)
df['subtot_correct'] = np.where(df['subtot_correct'] == 1, df['subtot_correct'], 0)
df = df.drop(['Sum', 'key'], axis=1)
Output: