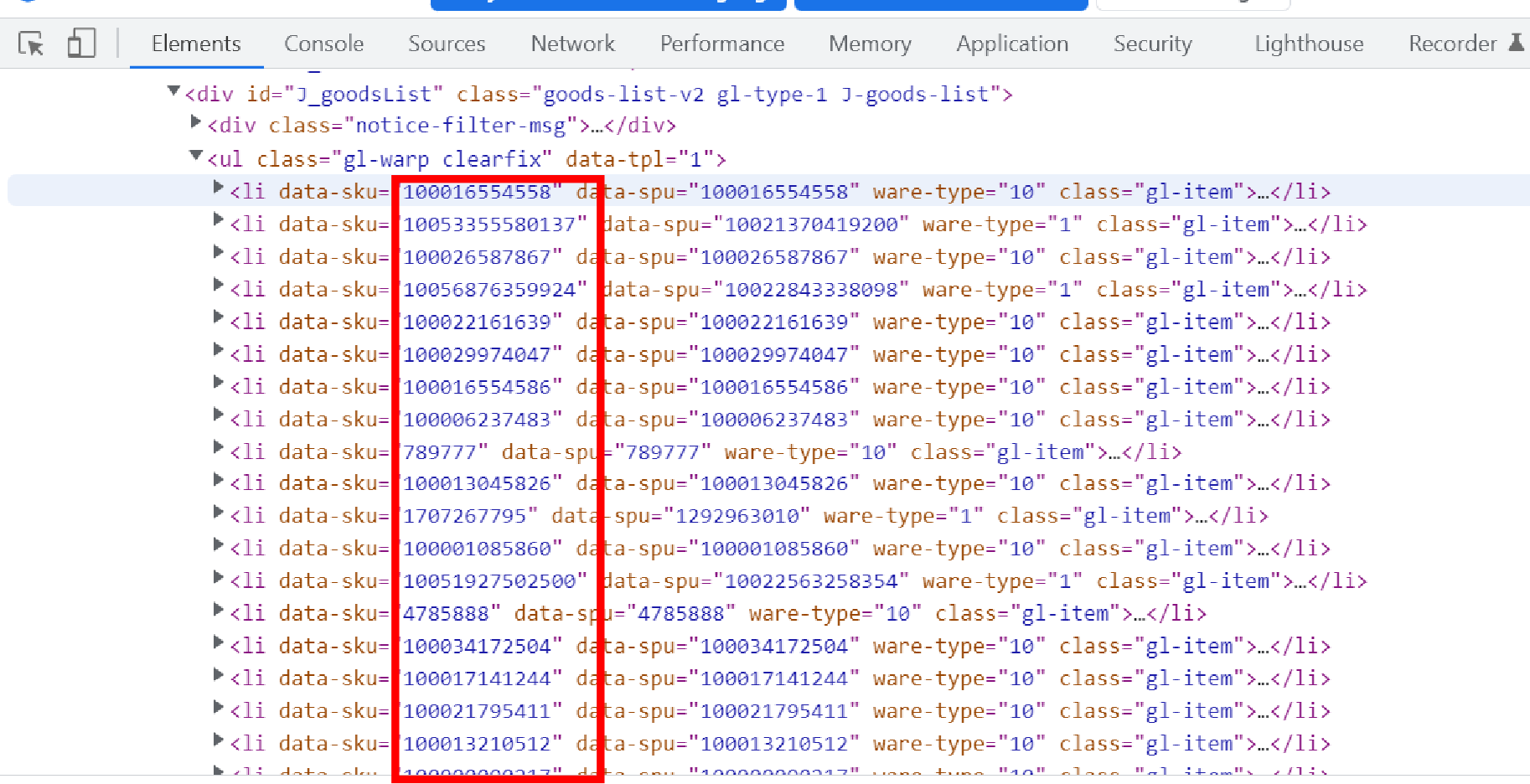
In python/selenium, how can I get the sku number in HTML code as in image? Blow code only can get text of the element, I want the content directly in the HTML. Thanks!
import time
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('https://search.jd.com/Search?keyword=果汁&qrst=1&wq=果汁&stock=1&pvid=b86735ca93754d6f96a68a4ee0e187d5&psort=3&click=0')
driver.execute_script("""
(function () {
var y = 0;
var step = 100;
window.scroll(0, 0);
function f() {
if (y < document.body.scrollHeight) {
y = step;
window.scroll(0, y);
setTimeout(f, 100);
} else {
window.scroll(0, 0);
document.title = "scroll-done";
}
}
setTimeout(f, 1000);
})();
""")
print("下拉中...")
# time.sleep(180)
while True:
if "scroll-done" in driver.title:
break
else:
print("还没有拉到最底端...")
time.sleep(3)
skus=driver.find_elements_by_xpath("//div[@id='J_goodsList']")
for sku in skus:
print(sku.text)
CodePudding user response:
You can get any element attribute value with .get_attribute method.
So, here you can do something like the following:
import time
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('https://search.jd.com/Search?keyword=果汁&qrst=1&wq=果汁&stock=1&pvid=b86735ca93754d6f96a68a4ee0e187d5&psort=3&click=0')
driver.execute_script("""
(function () {
var y = 0;
var step = 100;
window.scroll(0, 0);
function f() {
if (y < document.body.scrollHeight) {
y = step;
window.scroll(0, y);
setTimeout(f, 100);
} else {
window.scroll(0, 0);
document.title = "scroll-done";
}
}
setTimeout(f, 1000);
})();
""")
print("下拉中...")
# time.sleep(180)
while True:
if "scroll-done" in driver.title:
break
else:
print("还没有拉到最底端...")
time.sleep(3)
skus=driver.find_elements_by_xpath("//div[@id='J_goodsList']//li[@data-sku]")
for sku in skus:
print(sku.get_attribute("data-sku"))
CodePudding user response:
You were pretty close. Instead of targetting the ancestor <div> canonically you can target the descendant <li>. Finally, instad of extracting the text, you need to get_attribute("data-sku")
Solution
To extract and print the sku numbers e.g. 3313643, 5327144, etc you need to induce WebDriverWait for visibility_of_all_elements_located() and you can use either of the following Locator Strategies:
Using CSS_SELECTOR:
driver.get('https://search.jd.com/Search?keyword=果汁&qrst=1&wq=果汁&stock=1&pvid=b86735ca93754d6f96a68a4ee0e187d5&psort=3&click=0') print([my_elem.get_attribute("data-sku") for my_elem in WebDriverWait(driver, 20).until(EC.visibility_of_all_elements_located((By.CSS_SELECTOR, "div#J_goodsList ul li")))])Using XPATH:
driver.get('https://search.jd.com/Search?keyword=果汁&qrst=1&wq=果汁&stock=1&pvid=b86735ca93754d6f96a68a4ee0e187d5&psort=3&click=0') print([my_elem.get_attribute("data-sku") for my_elem in WebDriverWait(driver, 20).until(EC.visibility_of_all_elements_located((By.XPATH, "//div[@id='J_goodsList']//ul//li")))])Console Output:
['3313643', '5327144', '1256816', '3127041', '100007725801', '7153462', '100020544789', '3088504', '2439951', '4602877', '100013213444', '100018630091', '10028327196597', '100005772043', '3081867', '1044735', '4323156', '100010085943', '848890', '100010783078', '4377126', '3557308', '5417682', '100020805609', '4641871', '100017615158', '100032110985', '848893', '100013210524', '100017615166']Note : You have to add the following imports :
from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.common.by import By from selenium.webdriver.support import expected_conditions as EC