I have a dataframe with multiple orders, A B and C.
Each order can have multiple entries, i.e. you can order several products in a basket I've left spaces in the the dataframe just to make it clearer
Order_ID Pen Pencil
Order_A 1 0
Order_A 1 0
Order_B 1 0
Order_B 1 0
Order_B 0 1
Order_C 0 1
I'd like to make a third column which is dependent on what items are in the basket as a whole. So if there are only pens in the basket, this column is Pens Only, and if there's a mixture, it will say Pens and Pencils
example output
Order_ID Pen Pencil output
Order_A 1 0 pen Only
Order_A 1 0 pen only
Order_B 1 0 pens and pencils
Order_B 1 0 pens and pencils
Order_B 0 1 pens and pencils
Order_C 0 1 pencil only
CodePudding user response:
You can melt, filter, aggregate as string and merge:
df.merge(df.melt('Order_ID', var_name='output')
.query('value == 1')
.drop_duplicates()
.groupby('Order_ID')
['output'].agg(', '.join),
left_on='Order_ID',
right_index=True
)
Or, for fun, using a dot product:
df2 = df.groupby('Order_ID').transform('max')
df['output'] = df2.dot(df2.add_suffix(', ').columns).str[:-2]
Output:
Order_ID Pen Pencil output
0 Order_A 1 0 Pen
1 Order_A 1 0 Pen
2 Order_B 1 0 Pen, Pencil
3 Order_B 1 0 Pen, Pencil
4 Order_B 0 1 Pen, Pencil
5 Order_C 0 1 Pencil
CodePudding user response:
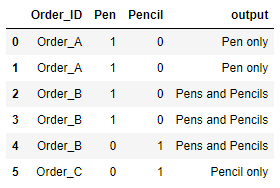
This code works for me.
To create a label mapping, I used a dict comprehension on records because pandas is not optimized for strings, so might as well use a Python loop as it has far less overhead than a pandas string operation.
# cross-tabulate df to calculate if pen and/or pencil exist in orders
totals = df.pivot_table(values=['Pen','Pencil'], index=['Order_ID'], aggfunc='any')
# convert the boolean values from totals to string values of columns
records = (totals*totals.columns).to_records()
# it's "pens and pencils" if both exist for an order ID and "... only" otherwise
labels = {k: f"{x or y} only" if '' in (x,y) else f"{x}s and {y}s" for k, x, y in records}
# map the label mapping
df['output'] = df['Order_ID'].map(labels)
df
CodePudding user response:
You can use transform to get the total sum and apply a pre-defined function:
def pen_pencil(row):
if (row.Pen.sum() >= 1) and (row.Pencil.sum() >= 1):
return 'pens and pencils'
elif row.Pen.sum() >= 1:
return 'pen only'
elif row.Pencil.sum() >= 1:
return 'Pencil Only'
df.groupby('Order_ID', as_index=False).transform('sum').apply(pen_pencil, axis=1)