TLDR:
A simple (single hidden-layer) feed-forward Pytorch model trained to predict the function y = sin(X1) sin(X2) ... sin(X10) substantially underperforms an identical model built/trained with Keras. Why is this so and what can be done to mitigate the difference in performance?
In training a regression model, I noticed that PyTorch drastically underperforms an identical model built with Keras.
This phenomenon has been observed and reported previously:
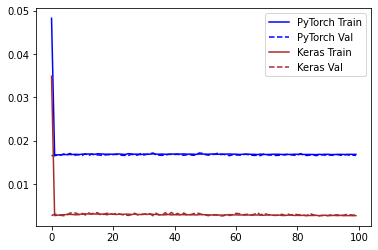
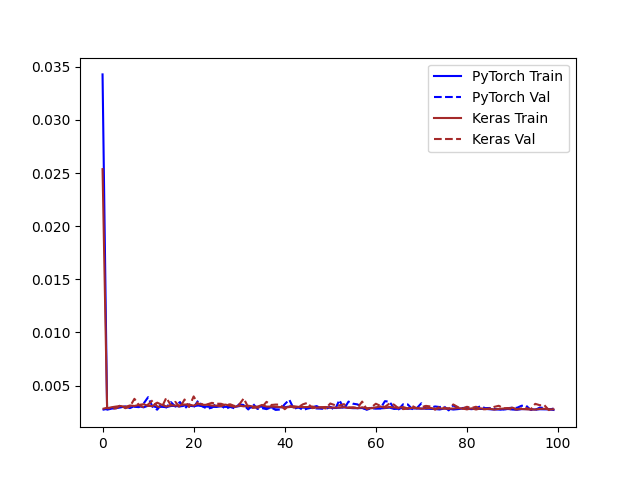
Keras records a much lower error in the training. Since this may be due to a difference in how Keras computes the loss, I calculated the prediction error on the validation set with sklearn.metrics.mean_squared_error
6. Validation error after training
ypred_keras = keras_model.predict(Xval).reshape(-1) ypred_torch = torch_model(torch.tensor(Xval, dtype=torch.float32)) ypred_torch = ypred_torch.detach().numpy().reshape(-1) mse_keras = metrics.mean_squared_error(yval, ypred_keras) mse_torch = metrics.mean_squared_error(yval, ypred_torch) print('Percent error difference:', (mse_torch / mse_keras - 1) * 100) r_keras = pearsonr(yval, ypred_keras)[0] r_pytorch = pearsonr(yval, ypred_torch)[0] print("r_keras:", r_keras) print("r_pytorch:", r_pytorch) plt.scatter(ypred_keras, yval); plt.title('Keras'); plt.show(); plt.close() plt.scatter(ypred_torch, yval); plt.title('Pytorch'); plt.show(); plt.close()Percent error difference: 479.1312469426776 r_keras: 0.9115184443702814 r_pytorch: 0.21728812737220082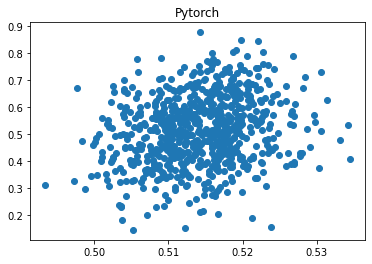
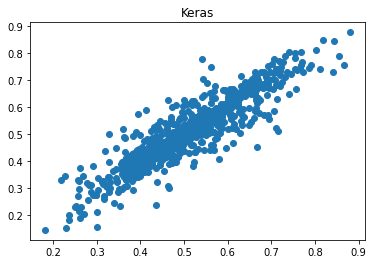
The correlation of predicted values with ground truth is 0.912 for Keras but 0.217 for Pytorch, and the error for Pytorch is 479% higher!
7. Other trials I also tried:
- Lowering the learning rate for Pytorch (lr=1e-4), R increases from 0.217 to 0.576, but it's still much worse than Keras (r=0.912).
- Increasing the learning rate for Pytorch (lr=1e-2), R is worse at 0.095
- Training numerous times with different random seeds. The performance is roughly the same, regardless.
- Trained for longer than 100 epochs. No improvement was observed!
- Used
torch.nn.init.xavier_uniform_instead oftorch.nn.init.xavier_normal_in the initialization of the weights. R improves from 0.217 to 0.639, but it's still worse than Keras (0.912).
What can be done to ensure that the PyTorch model converges to a reasonable error comparable with the Keras model?
CodePudding user response:
The problem here is unintentional broadcasting in the PyTorch training loop.
The result of a
nn.Linearoperation always has shape[B,D], whereBis the batch size andDis the output dimension. Therefore, in yourmean_squared_errorfunctionypredhas shape[32,1]andytruehas shape[32]. By the