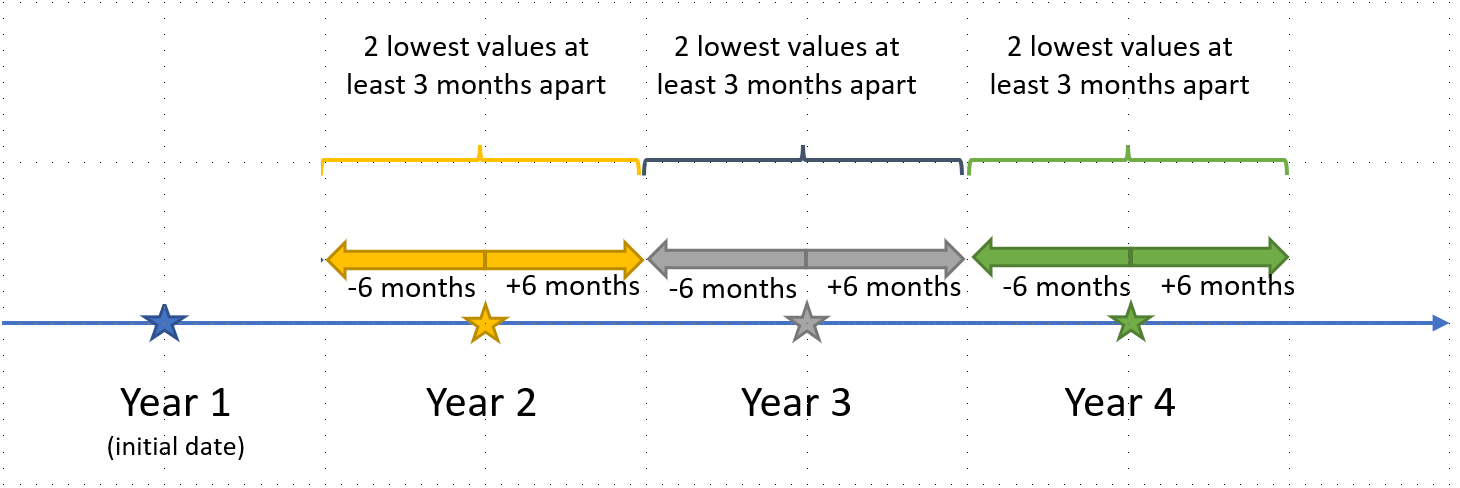
I would like to obtain the 2 lowest values which are at least 3 months apart within a one-year interval.
This is the pseudo-code that I am thinking of:
- Join
df1anddf2by ID - Group by ID and filter DATE within 1 year from INITIAL_DATE.
- Extract the lowest 2 RESULT
- Ensure they are at least 3 months apart. Else, exclude the second lowest and extract the third lowest RESULT (this is the part where I don't know how to proceed)
- EDIT Repeat for Year 3 and Year 4.
Sample input data looks like this:
df1 <- read.table(text = "
ID INITIAL_DATE
1 02/04/2015
2 06/01/2015", stringsAsFactors = FALSE, header = TRUE)
df2 <- read.table(text = "
ID DATE RESULT
1 18/08/2015 93
1 28/10/2015 85
1 16/12/2015 49
1 12/01/2016 58
1 06/03/2016 65
1 17/03/2016 86
1 07/04/2016 79
1 28/06/2016 90
1 09/10/2016 44
1 24/10/2016 51
1 08/11/2016 72
1 03/02/2017 46
1 05/04/2017 50
1 12/05/2017 92
1 26/08/2017 56
1 03/11/2017 56
1 01/01/2018 93
1 15/03/2018 59
1 23/04/2018 80
1 16/07/2018 53
1 28/11/2018 100
2 06/05/2015 34
2 20/12/2015 23
2 21/02/2016 25
2 12/05/2016 54
2 20/03/2017 45
2 05/05/2017 39
2 02/06/2017 47
2 23/11/2017 56
2 03/03/2018 65
2 19/06/2018 45", stringsAsFactors = FALSE, header = TRUE)
Sample output:
final_df <- read.table(text = "
ID YEAR DATE RESULT
1 YEAR2 16/12/2015 49
1 YEAR2 07/04/2016 79
1 YEAR3 09/10/2016 44
1 YEAR3 03/02/2017 46
1 YEAR4 03/11/2017 56
1 YEAR4 16/07/2018 53
2 YEAR2 20/12/2015 23
2 YEAR2 12/05/2016 54
2 YEAR3 NA NA
2 YEAR4 23/11/2017 56
2 YEAR4 19/06/2018 45", stringsAsFactors = FALSE, header = TRUE)
Appreciate any suggestions or help with this! I'm more familiar with tidyverse, but happy to learn data.table format too!
Thank you in advance!
Added some code sample to generate the output that I want. The code works but would like to see if there are more efficient ways to do this as my data has more than 20 million rows.
pacman::p_load(dplyr, lubridate, tidyr, stringr, magrittr)
df2 %<>%
left_join(df1) %>%
mutate(DATE = dmy(DATE),
INITIAL_DATE = dmy(INITIAL_DATE),
DATE2 = INITIAL_DATE %m % years(1),
YEAR2 = if_else(DATE %within% interval(DATE2 %m-% days(180), DATE2 %m % days(180)), 1L, 0L),
DATE3 = INITIAL_DATE %m % years(2),
YEAR3 = if_else(DATE %within% interval(DATE3 %m-% days(180), DATE3 %m % days(180)), 1L, 0L),
DATE4 = INITIAL_DATE %m % years(3),
YEAR4 = if_else(DATE %within% interval(DATE4 %m-% days(180), DATE4 %m % days(180)), 1L, 0L)) %>%
pivot_longer(cols = starts_with("Y"),
values_to = "include") %>%
filter(include == 1L) %>%
select(-matches("^DATE.$"), -include)
df2
year_min <- df2 %>%
group_by(ID, name) %>%
# obtain the lowest result for each year
slice_min(RESULT) %>%
ungroup() %>%
pivot_wider(id_cols = c(ID, INITIAL_DATE),
names_from = "name",
values_from = c("DATE", "RESULT"))
# Find the second lowest RESULT for YEAR 2 which is at least 30 days from DATE_Y2
year2 <- year_min %>%
left_join(df2 %>% filter(name=="YEAR2")) %>%
filter(abs(difftime(DATE_YEAR2, DATE, units = "days")) >= 90) %>%
group_by(ID) %>%
slice_min(RESULT) %>%
ungroup() %>%
select(ID, INITIAL_DATE, matches("^(DATE|RESULT)_"), DATE_YEAR2_2 = DATE, RESULT_YEAR2_2 = RESULT)
year2
# Find the second lowest RESULT for YEAR 3 which is at least 30 days from DATE_Y3
year3 <- year_min %>%
left_join(df2 %>% filter(name=="YEAR3")) %>%
filter(abs(difftime(DATE_YEAR3, DATE, units = "days")) >= 90) %>%
group_by(ID) %>%
slice_min(RESULT) %>%
ungroup() %>%
select(ID, INITIAL_DATE, matches("^(DATE|RESULT)_"), DATE_YEAR3_2 = DATE, RESULT_YEAR3_2 = RESULT)
year3
# Find the second lowest RESULT for YEAR 4 which is at least 30 days from DATE_Y4
year4 <- year_min %>%
left_join(df2 %>% filter(name=="YEAR4")) %>%
filter(abs(difftime(DATE_YEAR4, DATE, units = "days")) >= 90) %>%
group_by(ID) %>%
slice_min(RESULT) %>%
ungroup() %>%
select(ID, INITIAL_DATE, matches("^(DATE|RESULT)_"), DATE_YEAR4_2 = DATE, RESULT_YEAR4_2 = RESULT)
year4
final_df <- full_join(year_min, year2) %>%
full_join(year3) %>%
full_join(year4)
final_df
final_df %>%
pivot_longer(cols = -c(ID, INITIAL_DATE),
names_pattern = "(DATE|RESULT)_(YEAR.*)",
names_to = c(".value", "YEAR")) %>%
mutate(YEAR = str_remove(YEAR, "_.")) %>%
arrange(ID, YEAR, RESULT) %>%
group_by(ID, YEAR)
CodePudding user response:
Here is an approach that uses a helper function to look at all pairwise combinations of difference-in-days between a set of dates, filters those combinations with >=90 differences, and returns the indexes (rows) that have the lowest values
- Helper function
f <- function(d,v) {
if(length(d)<2) return(NA)
rows = do.call(rbind,combn(
1:length(d),2, function(x) data.frame(r1 = x[1], r2 = x[2], ddiff = d[x[2]] - d[x[1]], v1= v[x[1]], v2 = v[x[2]]),simplify=F)
) %>%
filter(ddiff>=90) %>%
arrange(v1,v2) %>%
slice_head(n=1) %>%
select(r1,r2) %>%
t()
if(dim(rows)[2]==0) return(NA)
rows[,1]
}
- Pipeline to join, create
YEAR, and callf()on theID/YEARgroups
library(tidyverse)
inner_join(df1,df2,by="ID") %>%
mutate(across(2:3, ~as.Date(.x, "%d/%m/%Y"))) %>%
group_by(ID) %>%
mutate(YEAR = ceiling(as.numeric((DATE-INITIAL_DATE 365.25/2) / 365.25))) %>%
arrange(ID,YEAR, DATE) %>%
group_by(ID,YEAR) %>%
filter(row_number() %in% f(DATE,RESULT))
Output:
ID INITIAL_DATE DATE RESULT YEAR
<int> <date> <date> <int> <dbl>
1 1 2015-04-02 2015-12-16 49 2
2 1 2015-04-02 2016-04-07 79 2
3 1 2015-04-02 2016-10-09 44 3
4 1 2015-04-02 2017-02-03 46 3
5 1 2015-04-02 2017-11-03 56 4
6 1 2015-04-02 2018-07-16 53 4
7 2 2015-01-06 2015-12-20 23 2
8 2 2015-01-06 2016-05-12 54 2
9 2 2015-01-06 2017-11-23 56 4
10 2 2015-01-06 2018-06-19 45 4