This seems simple but finding it really hard to suss out tried a tonne of stuff.
Basically I want to search the dom with js and find every instance of a word and replace it with another one. This is easy to do.
function replaceAllText(text) {
var walker = document.createTreeWalker(
document.body,
NodeFilter.SHOW_ELEMENT,
null,
false
);
while (walker.nextNode()) {
walker.currentNode.innerHTML = walker.currentNode.innerHTML.replaceAll(/hello/ig, text);
}
}
replaceAllText('Holla');
The hard bit is I want to do it only on certain tags for instance I dont want it to replace text inside A tags.
Now I thought skipping A tags would be easy I could do it like this.
function replaceAllText(text) {
var walker = document.createTreeWalker(
document.body,
NodeFilter.SHOW_ELEMENT,
null,
false
);
while (walker.nextNode()) {
if (walker.currentNode.tagName !== 'A') {
walker.currentNode.innerHTML = walker.currentNode.innerHTML.replaceAll(/hello/ig, text);
}
}
}
replaceAllText('Holla');
This still places the text inside A tags.
I have an example here I am testing with 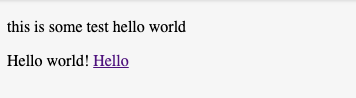
To this see its replacing all instances of hello with holla except inside the A tag.
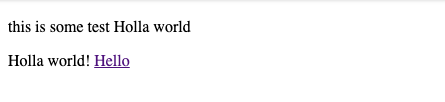
CodePudding user response:
We need to look at the text nodes then
Note that the body in a stacksnippet includes the whole document so I exclude the script tag too
Also note I create a regex and test and replace case INsensitive
Lastly I also ignore tags INSIDE a link
const replaceAllText = (fromText, toText) => {
document.body.querySelectorAll("*")
.forEach(tag => {
if (tag.closest("A")) return; // A and nested tags inside A tags
if (["SCRIPT"].includes(tag.tagName)) return; // we can add more here
[...tag.childNodes].forEach(node => {
if (node.nodeType === Node.TEXT_NODE) {
const nodeText = node.textContent;
if (!nodeText.toUpperCase().includes(fromText.toUpperCase())) return;
console.log(nodeText);
node.textContent = nodeText.replace(new RegExp(fromText,"ig"), toText)
}
});
});
}
replaceAllText('Hello','Holla');<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width">
<title>JS Bin</title>
</head>
<body>
<p>this is some test hello world</p>
<div >Hello world! <a href="">Hello</a></div>
<div >Hello world! <a href=""><span>Hello</span></a></div>
</body>
</html>CodePudding user response:
Your current approach looks good. You only need to take into account that innerHTML returns all html content, including nested tags. That's why your function replaced also text inside a tags.
One way to make it work is to take only text nodes, and filter out text nodes that are inside a tags, i.e. whose parent node's tag name is A.
var rejectScriptTextFilter = {
acceptNode: function(node) {
if (node.parentNode.nodeName !== 'A') {
return NodeFilter.FILTER_ACCEPT;
}
}
};
function replaceAllText(text) {
var walker = document.createTreeWalker(
document.body,
NodeFilter.SHOW_TEXT,
rejectScriptTextFilter,
false
);
while (walker.nextNode()) {
var node = walker.currentNode;
node.nodeValue = node.nodeValue.replaceAll(/hello/ig, text);
}
}
replaceAllText('Holla');<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width">
<title>JS Bin</title>
</head>
<body>
<p>this is some test hello world</p>
<div >Hello world! <a href="">Hello</a></div>
</body>
</html>