I am trying to build a scraper for Linkedin Jobs. I have been getting errors again and again because I am having difficulty in parsing links out of HTML files.
Here's the code I have written:
page_source=BeautifulSoup(driver.page_source,'lxml')
job_card = page_source.find_all('div', class_='base-card relative w-full hover:no-underline focus:no-underline base-card--link base-search-card base-search-card--link job-search-card')
for job in job_card:
job_title= job.find('h3',class_='base-search-card__title').text.replace(' ','')
job_company_name = job.find('h4',class_='base-search-card__subtitle').text.replace(' ','')
job_link_post = job.find('href',class_='base-card__full-link absolute top-0 right-0 bottom-0 left-0 p-0 z-[2]').text.replace(' ','')
print(f'Title = {job_title}\n'
f'Company Name = {job_company_name}\n'
f'Job Link = {job_link_post}\n')
I know I can't parse HTML with text, but I have tried several ways still I am getting this error. Any help will be appreciated. Thank you so much!
EDIT
Sharing a screenshot of the href class I am using: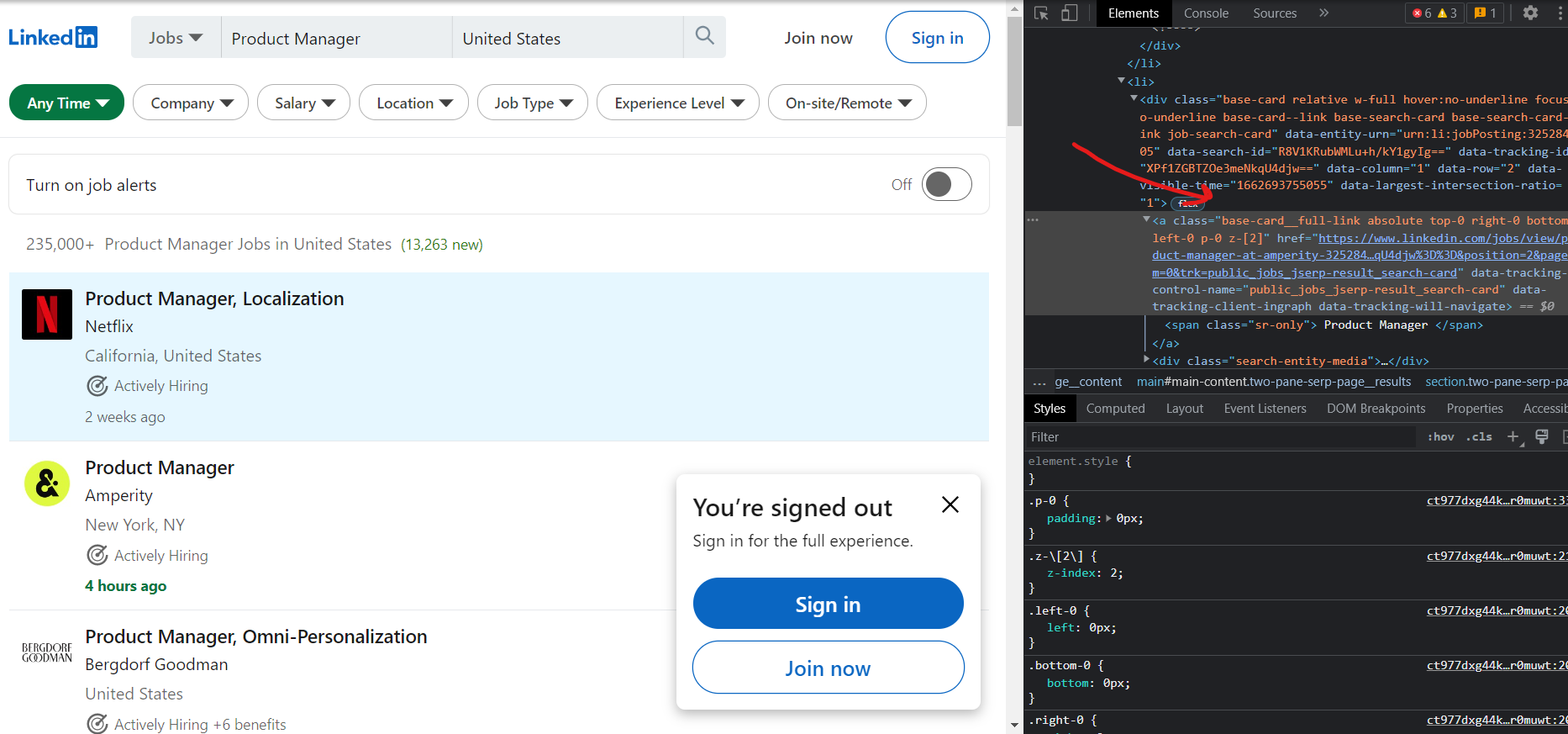
CodePudding user response:
One of your .find() calls is not finding what it's looking for and returning None instead. You need to break those statements into two and handle that case, like this:
elem = job.find('h3',class_='base-search-card__title')
if elem is not None:
job_title = elem.text.replace(' ','')
else:
# handle or report the error
raise ValueError(f"Could not find job title in {job}")
Depending on the situation, you might do various other things in the else clause, such as using a placeholder value:
job_title = '[unknown]'
or skipping the entry and continuing with the next one:
continue
CodePudding user response:
Main issue is that you try to find the link by attribute and not by tag:
job.find('href',class_='base-card__full-link absolute top-0 right-0 bottom-0 left-0 p-0 z-[2]')
That wont work that way and will result in None, instead use:
job.a.get('href)
There are also some other points you should be aware:
Try to select your elements more specific and use
idand HTML structure instead of chaining classes.Check if an element you try to find is available before calling methods.
Do not use
replace()in case of stripping, instead use.get_text(strip=True)
Example
for job in soup.select('.jobs-search__results-list li'):
job_title= job.h3.get_text(strip=True) if job.h3 else None
job_company_name = job.h4.get_text(strip=True) if job.h4 else None
job_link_post = job.a.get('href') if job.a else None
print(f'Title = {job_title}\n'
f'Company Name = {job_company_name}\n'
f'Job Link = {job_link_post}\n')