I am trying to solve a regression problem using pytorch. I have a pre-trained model to start with. When I was tuning hyperparameters, I found my batch size and train/validation loss have a weird correlation. Specifically:
batch size = 16 -\> train/val loss around 0.6 (for epoch 1)
batch size = 64 -\> train/val loss around 0.8 (for epoch 1)
batch size = 128 -\> train/val loss around 1 (for epoch 1)
I want to know if this is normal, or there is something wrong with my code.
optimizer: SGD with learning rate of 1e-3
Loss function:
def rmse(pred, real):
residuals = pred - real
square = torch.square(residuals)
sum_of_square = torch.sum(square)
mean = sum_of_square / pred.shape[0]
root = torch.sqrt(mean)
return root
train loop:
def train_loop(dataloader, model, optimizer, epoch):
num_of_batches = len(dataloader)
total_loss = 0
for batch, (X, y) in enumerate(dataloader):
optimizer.zero_grad()
pred = model(X)
loss = rmse(pred, y)
loss.backward()
optimizer.step()
total_loss = loss.item()
#lr_scheduler.step(epoch*num_of_batches batch)
#last_lr = lr_scheduler.get_last_lr()[0]
train_loss = total_loss / num_of_batches
return train_loss
test loop:
def test_loop(dataloader, model):
size = len(dataloader.dataset)
num_of_batches = len(dataloader)
test_loss = 0
with torch.no_grad():
for X, y in dataloader:
pred = model(X)
test_loss = rmse(pred, y).item()
test_loss /= num_of_batches
return test_loss
CodePudding user response:
The first batch of the first epoch is always going to be pretty inconsistent between runs unless you setup a manual rng seed. Your loss is a result of how well your randomly initialized weights do with your randomly subsampled batch of training items. In other words, its meaningless (in this context) what your loss is on this first go-around, regardless of batch-size.
CodePudding user response:
I'll start with an a. analogy, b. dive into the math, and then c. end with a numerical experiment.
a.) What you are witnessing is roughly the same phenomenon as the difference between stochastic and batched gradient descent. In the analog case, the "true" gradient or direction in which the learned parameters should be shifted minimizes the loss over the entire training set of data. In stochastic gradient descent, the gradient shifts the learned parameters in the direction that minimizes the loss for a single example. As the size of the batch is increased from 1 towards the size of the overall dataset, the gradient estimated from the minibatch becomes closer to the gradient for the whole dataset.
Now, is stochastic gradient descent useful at all, given that it is imprecise wrt the whole dataset? Absolutely. In fact, the noise in this estimate can be useful for escaping local minima in the optimization. Analogously, any noise in your estimate of loss wrt the whole dataset is likely nothing to worry about.
b.) But let's next look at why this behavior occurs. RMSE is defined as:
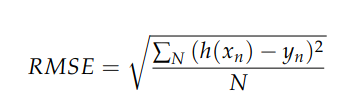
where N is the total number of examples in your dataset. And if RMSE were calculated this way, we would expect the value to be roughly the same (and to approach exactly the same value as N becomes large). However, in your case, you are actually calculating the mean epoch loss as:
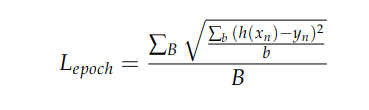
where B is the number of minibatches per epoch, and b is the number of examples per minibatch:
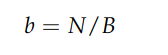
Thus, epoch loss is the average RMSE per minibatch. Rearranging, we can see:
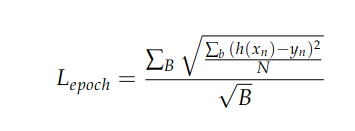
when B is large (B = N) and the minibatch size is 1,
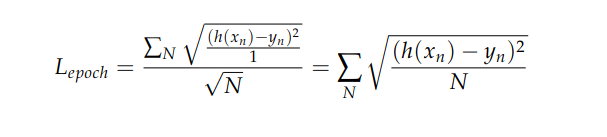
which clearly has quite different properties than RMSE defined above. However, as B becomes small B = 1, and minibatch size is N,
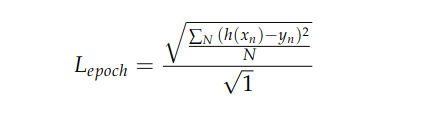
which is exactly equal to RMSE above. So as you increase the batch size, the expected value for the quantity you compute moves between these two expressions. This explains the (roughly square root) scaling of your loss with different minibatch sizes. Epoch loss is an estimate of RMSE (which can be thought of as the standard deviation of model prediction error). One training goal could be to drive this error standard deviation to zero, but your expression for epoch loss is also likely a good proxy for this. And both quantities are themselves proxies for whatever model performance you actually hope to obtain.
c. You can try this for yourself with a trivial toy problem. A normal distribution is used as a proxy for model error.
EXAMPLE 1: Compute RMSE for whole dataset ( of size 10000 x b)
import torch
for b in [1,2,3,5,9,10,100,1000,10000,100000]:
b_errors = []
for i in range (10000):
error = torch.normal(0,100,size = (1,b))
error = error **2
error = error.mean()
b_errors.append(error)
RMSE = torch.sqrt(sum(b_errors)/len(b_errors))
print("Average RMSE for b = {}: {}".format(N,RMSE))
Result:
Average RMSE for b = 1: 99.94982147216797
Average RMSE for b = 2: 100.38357543945312
Average RMSE for b = 3: 100.24600982666016
Average RMSE for b = 5: 100.97154998779297
Average RMSE for b = 9: 100.06820678710938
Average RMSE for b = 10: 100.12358856201172
Average RMSE for b = 100: 99.94219970703125
Average RMSE for b = 1000: 99.97941589355469
Average RMSE for b = 10000: 100.00338745117188
EXAMPLE 2: Compute Epoch Loss with B = 10000
import torch
for b in [1,2,3,5,9,10,100,1000,10000,100000]:
b_errors = []
for i in range (10000):
error = torch.normal(0,100,size = (1,b))
error = error **2
error = error.mean()
error = torch.sqrt(error)
b_errors.append(error)
avg = (sum(b_errors)/len(b_errors)
print("Average Epoch Loss for b = {}: {}".format(b,avg))
Result:
Average Epoch Loss for b = 1: 80.95650482177734
Average Epoch Loss for b = 2: 88.734375
Average Epoch Loss for b = 3: 92.08515930175781
Average Epoch Loss for b = 5: 95.56260681152344
Average Epoch Loss for b = 9: 97.49445343017578
Average Epoch Loss for b = 10: 97.20250701904297
Average Epoch Loss for b = 100: 99.6297607421875
Average Epoch Loss for b = 1000: 99.96969604492188
Average Epoch Loss for b = 10000: 99.99618530273438
Average Epoch Loss for b = 100000: 100.00079345703125