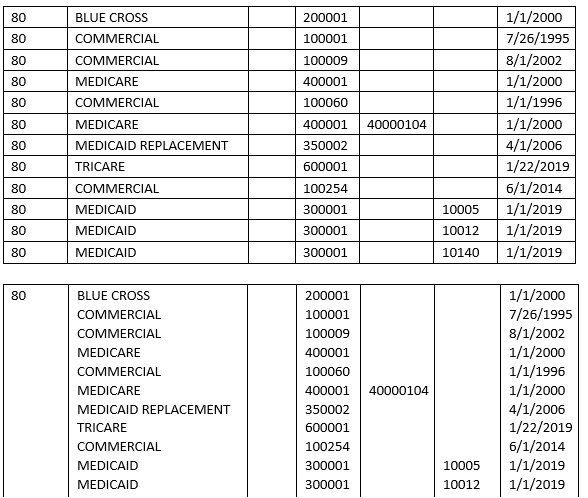
I have an excel file (top image) where I'm trying to essentially go from individual rows to merged rows and retain the order (bottom). I was thinking about using the groupby function but I don't really need to calculate anything just transform it. Any ideas would be greatly appreciated.
Sample Code:
{'ID': {0: 80, 1: 80, 2: 80, 3: 80, 4: 80},
'FINANCIAL CLASS RESTR': {0: 'BLUE CROSS',
1: 'COMMERCIAL',
2: 'COMMERCIAL',
3: 'MEDICARE',
4: 'COMMERCIAL'},
'PAYOR RESTR': {0: 200001, 1: 100001, 2: 100009, 3: 400001, 4: 100060},
'PLAN RESTR': {0: nan, 1: nan, 2: nan, 3: nan, 4: nan},
'LOCATION RESTR': {0: nan, 1: nan, 2: nan, 3: nan, 4: nan},
'EFFECTIVE FROM DATE': {0: 36526, 1: 34906, 2: 37469, 3: 36526, 4: 35065},
'ACTIVE FLAG': {0: 1, 1: 1, 2: 1, 3: 1, 4: 1}}
CodePudding user response:
This is 95% of the way there.
I just forced everything to be a string, built a list, then "\n".join()ed the string
This would not function as merged cells (merged cells give me chills), but would be human-readable in a similar way. Good luck.
newdf = {
"ID": [],
"FINANCIAL CLASS RESTR": [],
"PAYOR RESTR": [],
"PLAN RESTR": [],
"LOCATION RESTR": [],
"EFFECTIVE FROM DATE": [],
"ACTIVE FLAG": [],
}
for idval in df["ID"].unique():
newdf["ID"].append(idval)
q_val = df["ID"] == idval
temp = df.query("@q_val").drop(columns="ID")
for col in temp.columns:
temp[col] = temp[col].fillna("")
temp[col] = temp[col].astype("str")
col_vals = []
for x in temp[col]:
col_vals.append(x)
new_col_val = "\n".join(col_vals)
newdf[col].append(new_col_val)