I have a large csv file named 'grocery store transactions' loaded into Python that contains only 2 columns: a) transaction # and b) products bought during each transaction.
I am trying to do some Association Rule Mining, but before I can do that, I have to transform the dataset below:
txns = pd.read_csv('transactions.csv')
txns.head(15)

*** My dilemma is that I am trying to transform the one "Product" column into its corresponding categorical columns with 1s and 0s ***
*** Does anyone know how to transform my "Product" column into separate binary categorical columns?
Below is an example of how this should look like but using a different dataset from class. This is a bank csv file that had a single 'bank features' column transformed into separate categorical binary columns. 1 represents the customer had the bank feature and 0 means they do not.
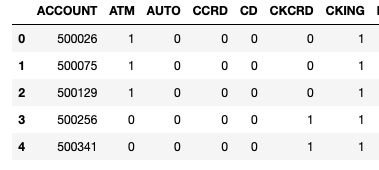
Any help would be greatly appreciated !!
CodePudding user response:
You can use either pandas or scikit-learn.
Pandas:
pd.get_dummies(df.Product, prefix='Product')
Scikit Learn:
from sklearn.preprocessing import LabelBinarizer
y = LabelBinarizer().fit_transform(df.Product)
For multicolumn data you can also use scikit-learn's OneHotEncoder, but I won't give an example here since you don't need it.