My data frame looks something like this with URLs instead of letters:
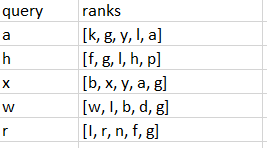
.csv code:
query,ranks
a,"[k, g, y, l, a]"
h,"[f, g, l, h, p]"
x,"[b, x, y, a, g]"
w,"[w, I, b, d, g]"
r,"[I, r, n, f, g]"
I want the outcome to be like this:

.csv code:
query,ranks,rank
a,"[k, g, y, l, a]",5
h,"[f, g, l, h, p]",4
x,"[b, x, y, a, g]",2
w,"[w, I, b, d, g]",1
r,"[I, r, n, f, g]",2
As you can see, each letter (URL) has been ranked according to its position.
Edit: Sometimes the 'ranks' value (dtype: list, of strings) doesn't have the 'query' value.
CodePudding user response:
A basic solution with apply and accounting for possibly missing values (I set -1 as default value but you can set whatever you need):
df = pd.DataFrame({'query': ['a', 'h', 'x', 'w', 'r'],
'ranks': [['k', 'g', 'y', 'l', 'a'],
['f', 'g', 'l', 'h', 'p'],
['b', 'x', 'y', 'a', 'g'],
['w', 'I', 'b', 'd', 'g'],
['I', 'r', 'n', 'f', 'g']]})
>>> df["rank"] = df.apply(lambda row: next((i for i,rank in enumerate(row.ranks, start=1) if rank == row.query), -1), axis=1)
>>> df
query ranks rank
0 a [k, g, y, l, a] 5
1 h [f, g, l, h, p] 4
2 x [b, x, y, a, g] 2
3 w [w, I, b, d, g] 1
4 r [I, r, n, f, g] 2