I am trying to load some data from ArcGis. I am used to working in Pandas Dataframes, not entirely sure how I can read from API's and get it in a nice table. I tried data['results'] and get feature dataset. But not sure how to organize the data by unique Object ID. Anyone have an idea how to read this into a pandas dataframe?
import urllib.request as urlopen
import urllib.parse as urlencode
import urllib.request as request
import json
import pandas as pd
inPts = {"geometryType" : "esriGeometryPoint",
"spatialReference" : {"wkid" : 54003},
'features':[{'geometry': {'x': -13308192.1956127, 'y': 4221903.58555983}}]}
dist = {'distance':8.5,'units':'esriMiles'}
data = {'Input_Observation_Point': inPts,
'Viewshed_Distance': dist,
'f': 'pjson'}
URL = 'http://sampleserver6.arcgisonline.com/ArcGIS/rest/services/Elevation/ESRI_Elevation_World/GPServer/Viewshed/execute'
req = request.Request(URL, urlencode.urlencode(data).encode('UTF-8'))
response = urlopen.urlopen(req)
response_bytes = response.read()
data = json.loads(response_bytes.decode('UTF-8'))
CodePudding user response:
If I understood right you want to create a dataframe for all the features and the geometry. The following code creates the dataframe bellow:
import urllib.request as urlopen
import urllib.parse as urlencode
import urllib.request as request
import json
import pandas as pd
import numpy as np
inPts = {"geometryType" : "esriGeometryPoint",
"spatialReference" : {"wkid" : 54003},
'features':[{'geometry': {'x': -13308192.1956127, 'y': 4221903.58555983}}]}
dist = {'distance':8.5,'units':'esriMiles'}
data = {'Input_Observation_Point': inPts,
'Viewshed_Distance': dist,
'f': 'pjson'}
URL = 'http://sampleserver6.arcgisonline.com/ArcGIS/rest/services/Elevation/ESRI_Elevation_World/GPServer/Viewshed/execute'
req = request.Request(URL, urlencode.urlencode(data).encode('UTF-8'))
response = urlopen.urlopen(req)
response_bytes = response.read()
data = json.loads(response_bytes.decode('UTF-8'))#
arcgis_data = data["results"][0]["value"]
columns = ["geometry"]
attributes = []
for field in arcgis_data["fields"]:
columns.append(field["name"])
attributes.append(field["name"])
feature_values = []
for feature in arcgis_data["features"]:
feature_line = [feature["geometry"]]
for feature_name in attributes:
feature_line.append(feature["attributes"][feature_name])
feature_values.append(feature_line)
feature_df = pd.DataFrame(np.array(feature_values), columns=columns)
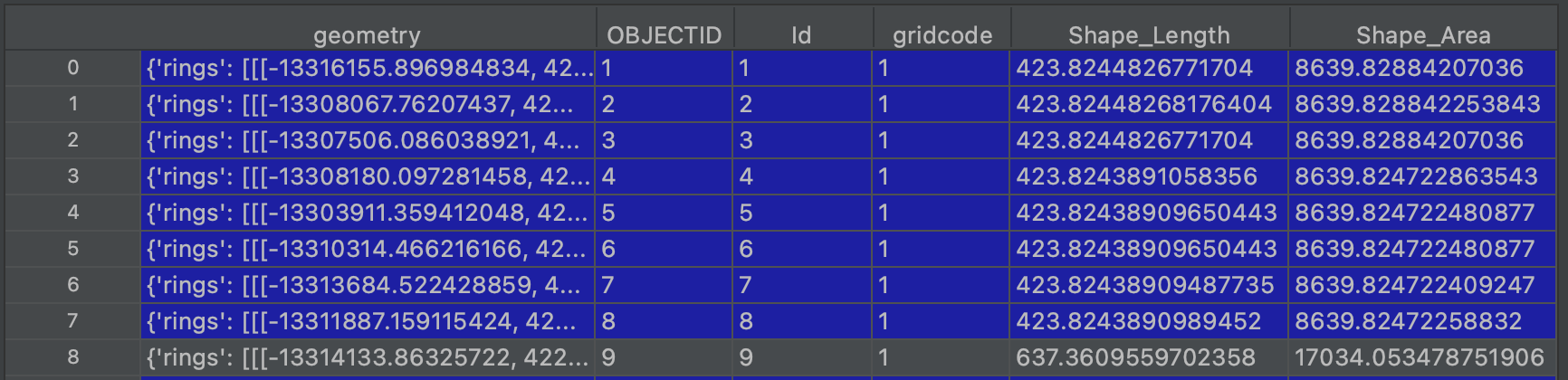
I tried to keep the code as dynamic as possible to handle more attribute names if the response at "fields" got more fields. Only two attributes that are always required is "geometry" and "attributes".