I'm trying to format some data once it's printed to the console in Python (I'm also using pandas if that helps.) Here's what I'm just trying to align vertically:
print("CensusTract State County Races")
for index, row in df.iterrows():
if row['Income'] >= 50000:
if row['Poverty'] > 50:
print(row['CensusTract'], row['State'], row['County'], end=" ")
if row['Hispanic'] > 1:
print("Hispanic:", row['Hispanic'], end=" ")
if row['White'] > 1:
print("White:", row['White'], end=" ")
etc. (ends with \n)
currently this code prints:
CensusTract State County Races
12071080100 Florida Lee Hispanic: 4.5 White: 74.7 Black: 20.8
13121003500 Georgia Fulton Hispanic: 4.8 White: 32.4 Black: 57.9 Asian: 1.1
15003008611 Hawaii Honolulu Hispanic: 9.7 White: 26.6 Asian: 2.4 Pacific: 51.6
17097863003 Illinois Lake Hispanic: 12.9 White: 61.5 Black: 13.4 Asian: 5.0
34023005100 New Jersey Middlesex Hispanic: 8.3 White: 60.4 Black: 7.3 Asian: 22.1
36119981000 New York Westchester Hispanic: 19.2 White: 30.4 Black: 29.6 Asian: 19.9
40109103602 Oklahoma Oklahoma Hispanic: 3.3 White: 60.0 Black: 29.3
Compared to what I want:
CensusTract State County Races
12071080100 Florida Lee Hispanic: 4.5 White: 74.7 Black: 20.8
13121003500 Georgia Fulton Hispanic: 4.8 White: 32.4 Black: 57.9 Asian: 1.1
15003008611 Hawaii Honolulu Hispanic: 9.7 White: 26.6 Asian: 2.4 Pacific: 51.6
17097863003 Illinois Lake Hispanic: 12.9 White: 61.5 Black: 13.4 Asian: 5.0
34023005100 New Jersey Middlesex Hispanic: 8.3 White: 60.4 Black: 7.3 Asian: 22.1
36119981000 New York Westchester Hispanic: 19.2 White: 30.4 Black: 29.6 Asian: 19.9
40109103602 Oklahoma Oklahoma Hispanic: 3.3 White: 60.0 Black: 29.3
CodePudding user response:
You can save some trouble with the nested for loops and iterating through rows by writing your queries in pandas.
df[(df['Income'] >= 50000) & (df['Poverty'] > 50)][['CensusTract', 'State', 'County', 'Hispanic', 'White', 'Black', 'Asian', 'Pacific']]
The above code tells pandas to look for rows where the income is >= 50000 AND the poverty is above 50. Then we are telling it to only show us the columns that we want to see with [['column 1', 'column 2']] etc.
This is what you should see after running the line of code:
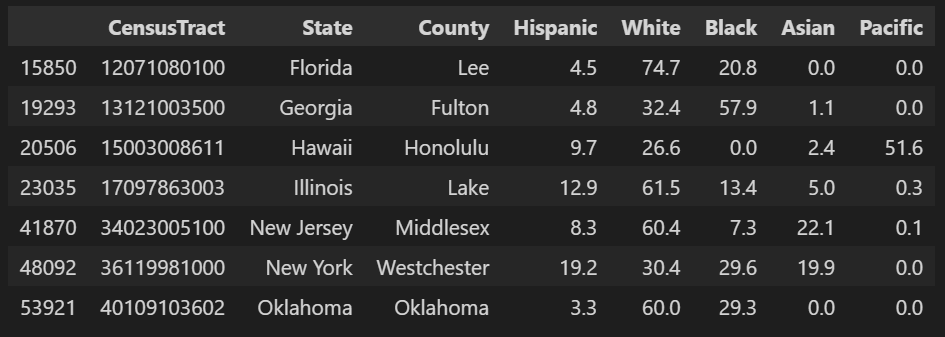
CodePudding user response:
Formatting with f-strings or with usage of .rjust() ( see: https://docs.python.org/3/tutorial/inputoutput.html#manual-string-formatting ) gives you full flexibility about how much columns you have printed. This can't be done by a Pandas table which must provide all the columns for printout:
print("CensusTract State County Races")
maxState = len(maxLenColumnStateStrRepresentation)
maxCounty = len(maxLenColumnCountyStrRepresentation)
# ... with Hispanic, White, Black == 10 for label and 4 for number
for index, row in df.iterrows():
if row['Income'] >= 50000:
if row['Poverty'] > 50:
print(f'{row['CensusTract']}, {row['State']:maxState}, {row['County':maxCounty]}', end=" ")
CensusTract State County Races
12071080100 Florida Lee Hispanic: 4.5 White: 74.7 Black: 20.8
13121003500 Georgia Fulton Hispanic: 4.8 White: 32.4 Black: 57.9 Asian: 1.1
15003008611 Hawaii Honolulu Hispanic: 9.7 White: 26.6 Asian: 2.4 Pacific: 51.6
# or
for index, row in df.iterrows():
if row['Income'] >= 50000:
if row['Poverty'] > 50:
print(f'row['CensusTract'], row['State'].rjust(maxState), row['County':maxCounty].rjust(maxCounty)', end=" ")
For optimal result you have to collect all the data to calculate the maxWidth of all the chosen results or take the overall maxWidth of the entire column if you not after minimal possible line width of the printout.