I'm trying to scrape text from a website with BeautifulSoup, and everything works well except for the fact that it's only scraping text from the top part of the page:
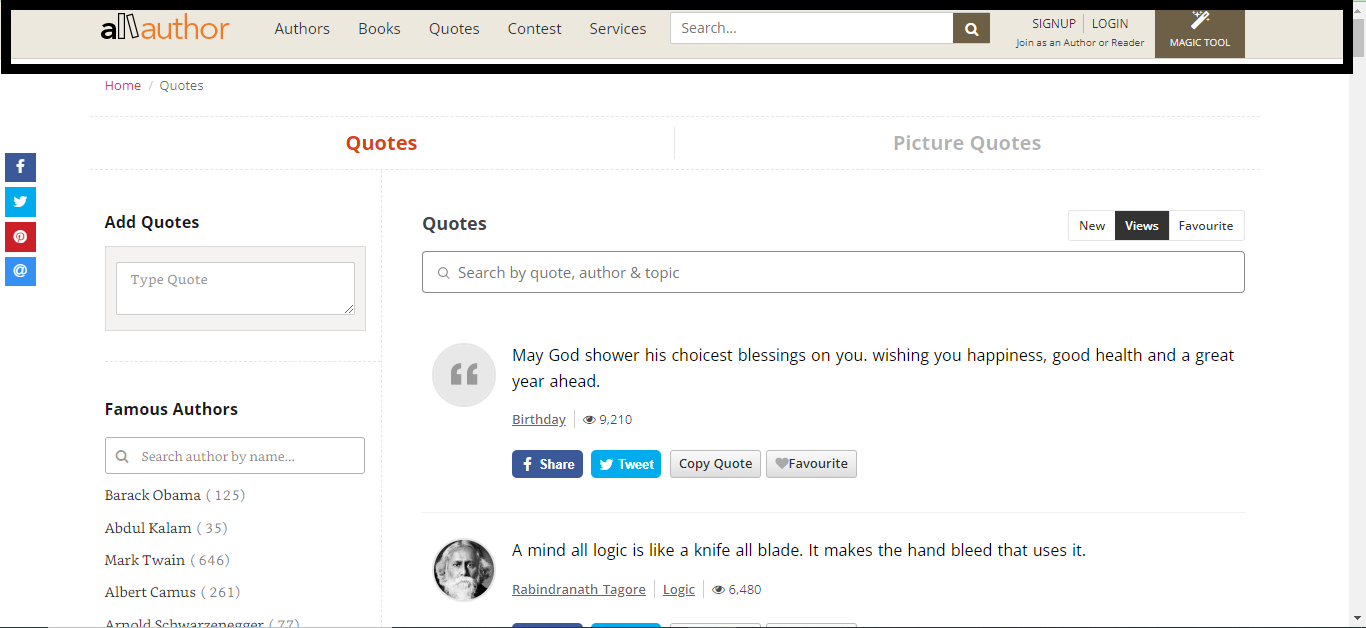
Output:
Toggle navigation
Authors
Author Directory
Amazon’s Top 100
USA Today
New York Times
Author Interview
Author's Top 5 Tips
Authors Pool
Join as an Author
Books
Book Directory
Free Books
#1 Best Seller Books
Signed Paperback
Audio Books
Free with Kindle Unlimited
Limited Time Deals
Book Teaser
Feature Your Book
Quotes
Famous Quotes
Picture Quotes
Quotes By Author
Quotes By Topic
Quote of the Day
Contest
Cover of the Month Voting
Cover of the Month Winners
Cover of the Month Submission
Services
SERVICES
Promotional Plans
Author Program
Feature Your Book
TOOLS
Review GIF Maker
Seasonal Mockup Banner
Promotional GIF Banners
ABOUT
About us
Blog
FAQ
Testimonial
Contact
Search
SIGNUP
LOGIN Join as an Author or Reader
Magic Tool
Magic Tool
Seasonal Mockup
Image Editor
Quotes Editor
Authors
Author Directory
Amazon’s Top 100
USA Today
New York Times
Author Interview
Author's Top 5 Tips
Authors Pool
Join as an Author
Books
Book Directory
Free Books
#1 Best Seller Books
Signed Paperback
Audio Books
Free with Kindle Unlimited
Limited Time Deals
Book Teaser
Feature Your Book
Quotes
Famous Quotes
Picture Quotes
Quotes By Author
Quotes By Topic
Quote of the Day
Contest
Cover of the Month Voting
Cover of the Month Winners
Cover of the Month Submission
Services
SERVICES
Promotional Plans
Author Program
Feature Your Book
TOOLS
Review GIF Maker
Seasonal Mockup Banner
Promotional GIF Banners
ABOUT
About us
Blog
FAQ
Testimonial
Contact
Search
SIGNUP
LOGIN Join as an Author or Reader
Magic Tool
Magic Tool
Seasonal Mockup
Image Editor
Quotes Editor
Search
Process finished with exit code 0
I don't want text from that part of the page, I only want the right side. I was thinking that one possibility for my error might be the fact that the rest of the text in the website is comprised of links and not regular text, but if that's the case how do I get the text for links? What am I doing wrong, and how can I scrape text from the right side of the website only?
My code:
import bs4 as bs
import urllib.request
source = urllib.request.urlopen('https://allauthor.com/quotes/').read()
soup = bs.BeautifulSoup(source,'lxml')
div = soup.div
for text in div.find_all("div"):
print(text.text)
CodePudding user response:
Content is served dynamically, data comes from an additional POST resquest. While requests do not render dynamic contents like a browser will do, you won`t get the expected data exactly this way.
You could perform an POST request and scrape the data from the results to get your goal.
Example
Simply adjust the range() to get more, I limited it for demonstration purposes:
import requests
from bs4 import BeautifulSoup
quotes = []
for i in range(0,1000,100):
url = f'https://allauthor.com/getQuotesDirectory.php?start={i}&length=100&orderby=usersView desc'
headers = {'user-agent': 'Mozilla/5.0', 'cookies':''}
data = requests.post(url, headers=headers).json()['aaData']
soup = BeautifulSoup(''.join([j for i in data for j in i]))
for t in soup.select('div.quote-list'):
quotes.append({
'quote':t.a.text,
'category':t.div.a.text,
'views':t.div.span.text
})
quotes
Output
[{'quote': 'May God shower his choicest blessings on you. wishing you happiness, good health and a great year ahead.',
'category': 'Birthday',
'views': ' 9,210'},
{'quote': 'A mind all logic is like a knife all blade. It makes the hand bleed that uses it.',
'category': ' Rabindranath Tagore',
'views': ' 6,480'},
{'quote': 'Reality of life When you give importance to people they think that you are always free But They dont understand that you make yourself available for them every time.',
'category': 'New Collection',
'views': ' 6,171'},
{'quote': 'Xcuse me, I found something under my shoes. Oh its your attitude.',
'category': 'Attitude',
'views': ' 6,024'},
{'quote': 'Truth is I miss you. All the time, every second, every minute, every hour, every day.',
'category': 'Missing You',
'views': ' 5,472'},...]