Currently I am using this statement to find all columns in a dataframe that has no missing values, it works fine. but I'm wondering if there is more concise way (albeit, efficient way) to do the same thing?
df.columns[ np.sum(df.isnull()) == 0 ]
CodePudding user response:
To better answer the question one would need to have access to the dataframe in question.
Without it, there are various method one can use.
Let's consider the following dataframe as example
df = pd.DataFrame(np.random.randint(0, 100, size=(100, 4)), columns=list('ABCD'))
df.iloc[0:10, 0] = np.nan
[Out]:
A B C D
0 NaN 89 63 41
1 NaN 12 47 8
2 NaN 79 76 67
3 NaN 87 61 38
4 NaN 28 31 30
Method 1 - As OP indicated (we will be use as reference)
df.columns[ np.sum(df.isnull()) == 0 ]Method 2 - Similar to Method 1, with
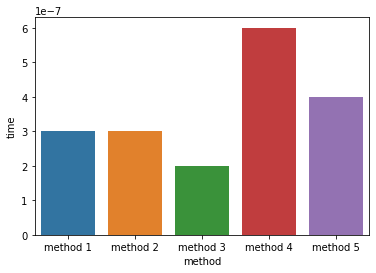
Again, this might change depending on the dataframe that one uses. Also, depending on the requirements (hardware, and business requirements), there might be other ways to achieve the same goal.
CodePudding user response:
You can use this:
df.isna().any() # returns all columns either True (column names that has MISSING values) False (column names has NO MISSING values) df.columns[df.isna().any()] # returns only the column names with MISSING values df.columns[~df.isna().any()] # tilda negates the condition # returns the columns with NO MISSING values df.columns[~df.isna().any()].tolist() # .tolist() converts the result to a list, if you wish.