My data looks like this,
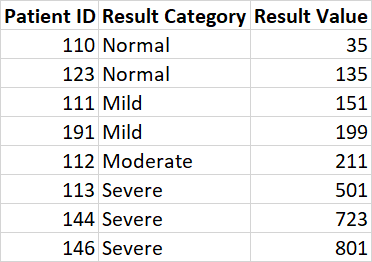
I've 4 distinct Result category: Normal, Mild, Moderate and Severe
I want to get count of patients for each categories and in case of severe category, I want to further divide it into more categories based on its corresponding Result value (e.g., Severe_500_to_599, Severe_600_to_699, Severe_700_to_799 and severe_>800) and then get the count of these sub categories.
So my Results should look like this,
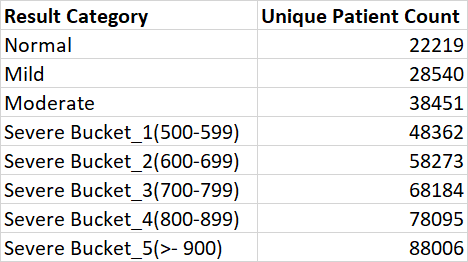
Currently I'm taking individual count by putting the specific condition,
select count(distinct SOURCE_PATIENT_ID)
from Table1
where RESULT_CATEGORY = 'SEVERE' and RESULT_VALUE_STANDARDIZED between '1100' and '1199' and RESULT_UNIT <> 'MG/DL';
Is there any way to get all the results in one single query?
Thanks!
CodePudding user response:
you can use Union all to combine your query´s
select 'SEVERE-599' as ResultCategory,
count(distinct SOURCE_PATIENT_ID)
from Table1
where RESULT_CATEGORY = 'SEVERE' and RESULT_VALUE_STANDARDIZED between '500' and '599' and RESULT_UNIT <> 'MG/DL'
Union ALL
select 'SEVERE-699' as ResultCategory,
count(distinct SOURCE_PATIENT_ID)
from Table1
where RESULT_CATEGORY = 'SEVERE' and RESULT_VALUE_STANDARDIZED between '600' and '699' and RESULT_UNIT <> 'MG/DL'
CodePudding user response:
Window function with QUALIFY clause can be used here to divide data sets into individual buckets and then get single value out of those bucket.
Following query -
with data (patient_id, result_category, result_value) as (
select * from values
(110,'Normal',35),
(123,'Normal',135),
(111,'Mild',151),
(191,'Mild',199),
(112,'Moderate',211),
(113,'Severe',501),
(115,'Severe',500),
(144,'Severe',723),
(146,'Severe',801)
)
select
case
when result_category = 'Severe'
AND result_value between 500 and 599
then
'Severe Bucket (500-599)'
when result_category = 'Severe'
AND result_value between 700 and 799
then
'Severe Bucket (700-799)'
when result_category = 'Severe'
AND result_value between 800 and 899
then
'Severe Bucket (800-899)'
else
result_category
end new_result_category,
sum(result_value) over (partition by new_result_category) patient_count
from data
qualify row_number() over (partition by new_result_category
order by patient_id desc) = 1;
Will give result as below -
| NEW_RESULT_CATEGORY | PATIENT_COUNT |
|---|---|
| Mild | 350 |
| Moderate | 211 |
| Severe Bucket (700-799) | 723 |
| Severe Bucket (500-599) | 1001 |
| Normal | 170 |
| Severe Bucket (800-899) | 801 |
CodePudding user response:
May I suggest the underrated grouping sets?
with cte as
(select *, case when result_value between 500 and 599 then 'Severe Bucket (500-599)'
when result_value between 700 and 799 then 'Severe Bucket (700-799)'
when result_value between 800 and 899 then 'Severe Bucket (800-899)'
end as breakdown
from data)
select coalesce(result_category,breakdown) as category,
count(distinct patient_id) as patient_count
from cte
group by grouping sets (result_category,breakdown)
having coalesce(result_category,breakdown) is not null