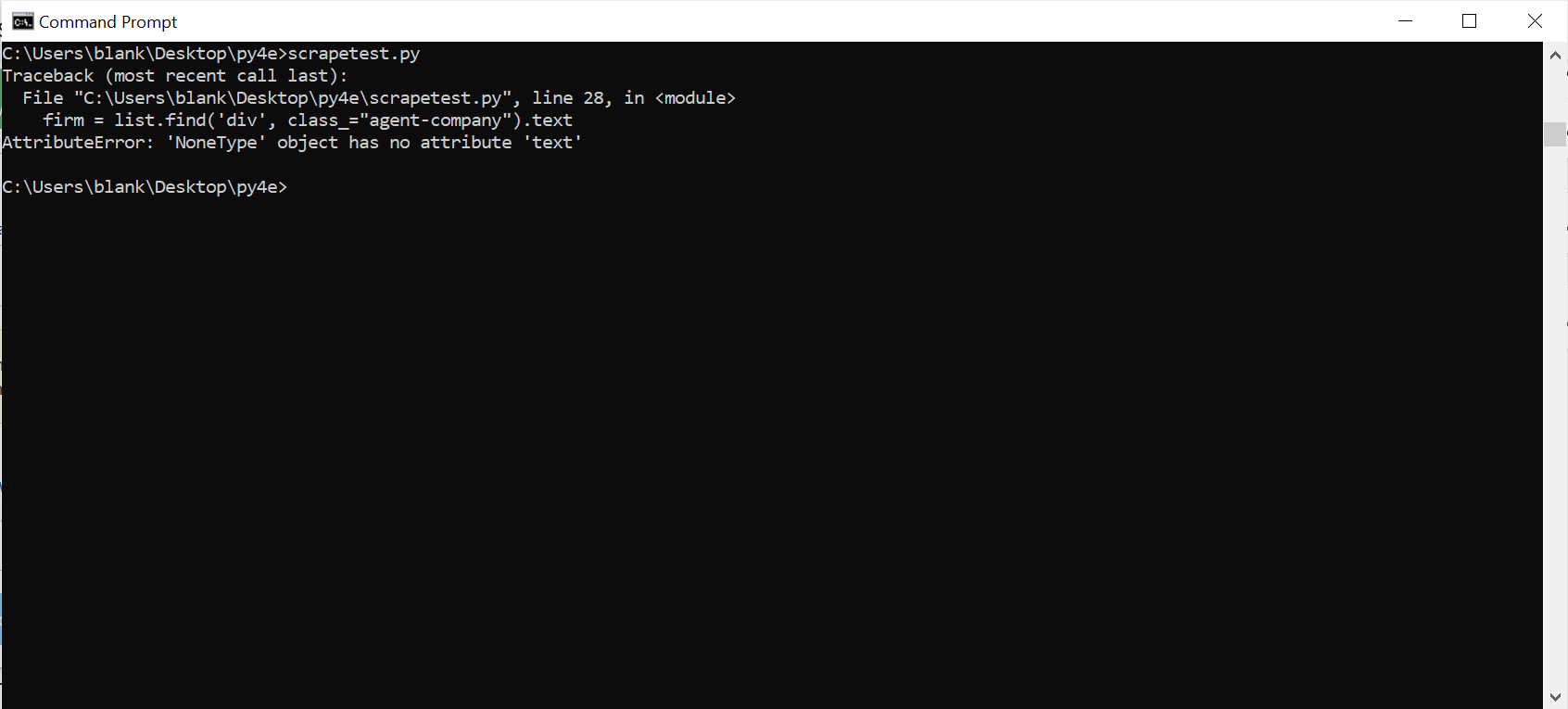
i am scraping a realestate website in python and im stuck trying to scrape the company name of the agents. I get a AttributeError: 'NoneType' object has no attribute 'text.
 Any help is appreciated.
Any help is appreciated.
from bs4 import BeautifulSoup
import requests
url = "https://www.point2homes.com/MX/Real-Estate-Listings.html?LocationGeoId=&LocationGeoAreaId=&Location=San Felipe, Baja California, Mexico"
page_scrape = requests.get(url)
soup = BeautifulSoup(page_scrape.content, 'html.parser')
lists = soup.find_all('article')
for list in lists:
address = list.find('div', class_="address-container").text
try:
beds = list.find('li', class_="ic-beds").text
except:
print("Data Not Logged")
try:
baths = list.find('li', class_="ic-baths").text
except:
print("Data not logged")
try:
size = list.find('li', class_="ic-sqft").text
except:
print("Data not logged")
type = list.find('li', class_="property-type ic-proptype").text
price = list.find('span', class_="green").text
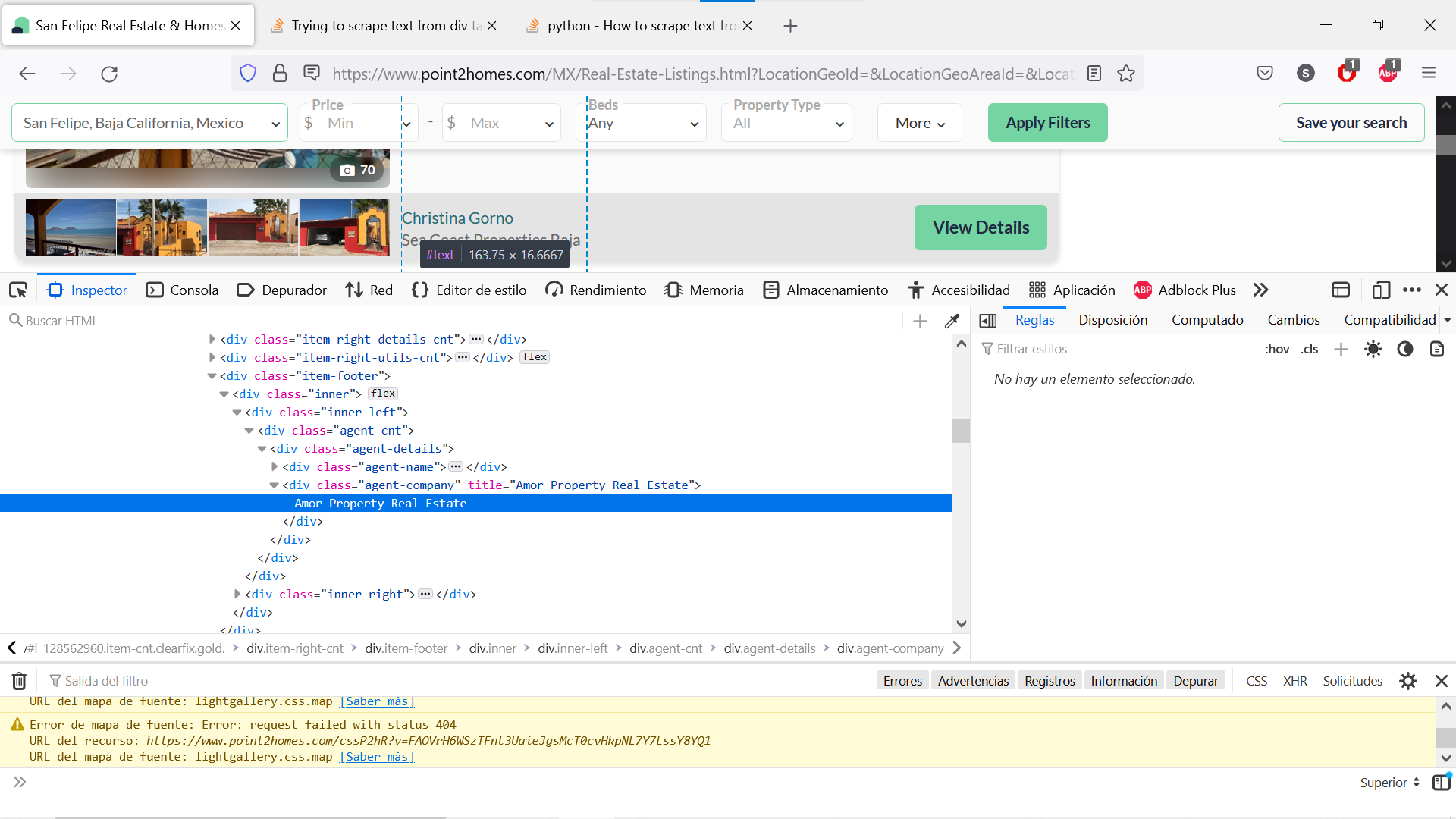
agent = list.find('div', class_="agent-name").text
firm = list.find('div', class_="agent-company").text
info = [address, beds, baths, size, type, price, agent, firm]
print(info)
CodePudding user response:
look like beautiful soup not work correctly with standart tag format but when you try print firm without .text the data is exist so u can do simple substring operation :
i try is work here the code:
from bs4 import BeautifulSoup
import requests
url = "https://www.point2homes.com/MX/Real-Estate-Listings.html?LocationGeoId=&LocationGeoAreaId=&Location=San Felipe, Baja California, Mexico"
headers = {"User-Agent": "Mozilla/5.0","Content-Type": "application/json"}
page_scrape = requests.get(url, headers=headers)
soup = BeautifulSoup(page_scrape.content, 'html.parser')
lists = soup.find_all('article')
for list in lists:
address = list.find('div', class_="address-container").text
try:
beds = list.find('li', class_="ic-beds").text
except:
print("Data Not Logged")
try:
baths = list.find('li', class_="ic-baths").text
except:
print("Data not logged")
try:
size = list.find('li', class_="ic-sqft").text
except:
print("Data not logged")
type = list.find('li', class_="property-type ic-proptype").text
price = list.find('span', class_="green").text
agent = list.find('div', class_="agent-name").text
firmstr = list.find('div', class_="agent-company")
firm=''
if firmstr is not None:
spl_word = '>'
firmstr2=str(firmstr)
res = firmstr2.split(spl_word, 1)
splitString = res[1]
res2 = splitString.split('<', 1)
splitString2 = res2[0]
firm=splitString2
info = [address, beds, baths, size, type, price, agent, firm]
print(info);