from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.chrome.service import Service as ChromeService
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.action_chains import ActionChains
import configparser
from datetime import datetime, timedelta, date
import time
import json
parser = configparser.RawConfigParser()
parser.read('config.ini')
pages=parser['PROPERTIES']['PAGE']
url= parser['PROPERTIES']['URL']
END_DATE = datetime.strptime(parser['DATE']['END'], '%Y-%m-%d')
START_DATE=datetime.strptime(parser['DATE']['START'],'%Y-%m-%d')
time.sleep(10)
# Setting up driver options
options = webdriver.ChromeOptions()
# Setting up Path to chromedriver executable file
CHROMEDRIVER_PATH =r'C:\Users\HP\Desktop\INTERNSHIP\Target\chromedriver.exe'
# Adding options
options.add_experimental_option("excludeSwitches", ["enable-automation"])
options.add_experimental_option("useAutomationExtension", False)
# Setting up chrome service
service = ChromeService(executable_path=CHROMEDRIVER_PATH)
# Establishing Chrom web driver using set services and options
driver = webdriver.Chrome(service=service, options=options)
driver.implicitly_wait(10)
wait = WebDriverWait(driver, 20)
time.sleep(2)
item_list=[]
for i in range(1,int(pages)):
url_main = url str(i)
driver.get(url_main)
# while True:
try:
reviews = wait.until(EC.visibility_of_all_elements_located((By.CSS_SELECTOR, ".review-item")))
for review in reviews:
this_review_date_string= review.find_element_by_xpath(".//time[contains(@class,'submission-date')]")
this_review_date_string_ago= this_review_date_string.text
date_today= date.today()
if "month" in this_review_date_string_ago:
date_period_string = this_review_date_string_ago.split("month")[0]
date_period_int = int(date_period_string)*30
temp_review_date = date_today - timedelta(days=date_period_int)
elif "day" in this_review_date_string_ago:
date_period_string=this_review_date_string_ago.split("day")[0]
date_period_int = int(date_period_string)
temp_review_date = date_today - timedelta(days=date_period_int)
elif "hour" in this_review_date_string_ago:
date_period_string=this_review_date_string_ago.split("hour")[0]
date_period_int = int(date_period_string)
temp_review_date = date_today - timedelta(hours=date_period_int)
elif "year" in this_review_date_string_ago:
date_period_string=this_review_date_string_ago.split("year")[0]
date_period_int = int(date_period_string)*365
temp_review_date = date_today - timedelta(days=date_period_int)
this_review_datetime = temp_review_date.strftime('%d %B %Y')
current_date= datetime.strptime( this_review_datetime, '%d %B %Y')
if (START_DATE< current_date < END_DATE):
item={
'stars': review.find_element_by_xpath(".//p[contains(@class,'visually-hidden')]").text.replace("out of 5 stars","").replace("Rated",""),
'username': review.find_element_by_xpath(".//div[contains(@class,'ugc-author')]").text,
'userurl':"NA",
'title':review.find_element_by_xpath(".//h4[contains(@class,'c-section-title review-title heading-5 v-fw-medium')]").text,
'review_text':review.find_element_by_xpath(".//div[contains(@class,'ugc-review-body')]//p[contains(@class,'pre-white-space')]").text,
'permalink': "NA",
'reviewlocation': "NA",
'reviewdate': this_review_datetime,
'subproductname': "NA",
'subproductlink': "NA",
}
item_list.append(item)
except:
break
print(item_list)
with open("output.json","r ") as
outfile:
json.dump(item_list,outfile)
I am trying to scrape 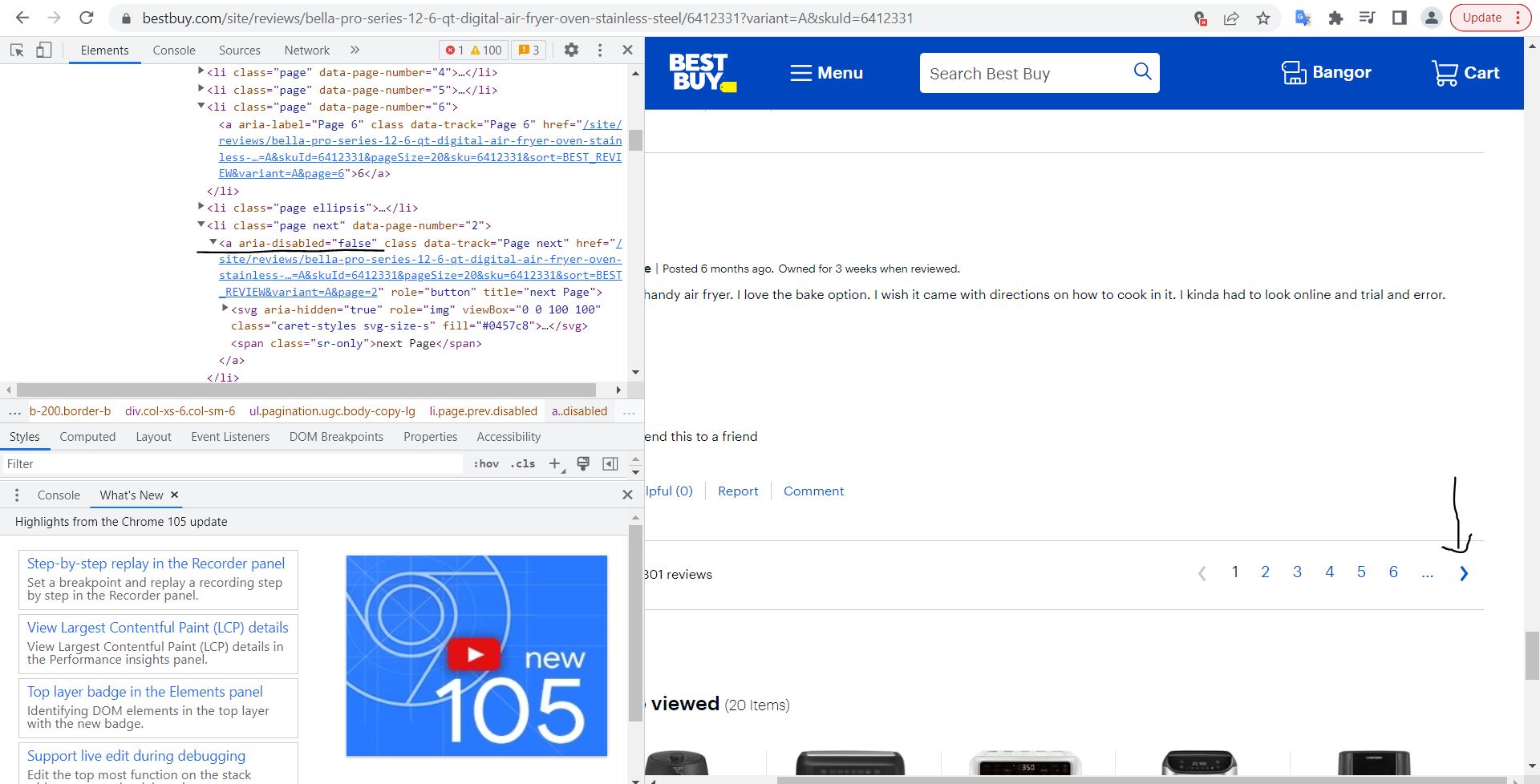
You need to find the nexpage element and get attribute of aria-disabled value true or false and you need to iterate in a while loop till aria-disable=false and perform you test.
here is the code:
nextPage = driver.find_element(By.XPATH, '//li[@class='page next']/a')
nextPageDisability = nextPage.get_attribute('aria-disabled')
while(nextPageDisability=='true':
nextPageDisability = nextPage.get_attribute('aria-disabled')
url_main = url str(i)
driver.get(url_main)
# while True:
try:
reviews = wait.until(EC.visibility_of_all_elements_located((By.CSS_SELECTOR, ".review-item")))
for review in reviews:
this_review_date_string= review.find_element_by_xpath(".//time[contains(@class,'submission-date')]")
this_review_date_string_ago= this_review_date_string.text
date_today= date.today()
if "month" in this_review_date_string_ago:
date_period_string = this_review_date_string_ago.split("month")[0]
date_period_int = int(date_period_string)*30
temp_review_date = date_today - timedelta(days=date_period_int)
elif "day" in this_review_date_string_ago:
date_period_string=this_review_date_string_ago.split("day")[0]
date_period_int = int(date_period_string)
temp_review_date = date_today - timedelta(days=date_period_int)
elif "hour" in this_review_date_string_ago:
date_period_string=this_review_date_string_ago.split("hour")[0]
date_period_int = int(date_period_string)
temp_review_date = date_today - timedelta(hours=date_period_int)
elif "year" in this_review_date_string_ago:
date_period_string=this_review_date_string_ago.split("year")[0]
date_period_int = int(date_period_string)*365
temp_review_date = date_today - timedelta(days=date_period_int)
this_review_datetime = temp_review_date.strftime('%d %B %Y')
current_date= datetime.strptime( this_review_datetime, '%d %B %Y')
if (START_DATE< current_date < END_DATE):
item={
'stars': review.find_element_by_xpath(".//p[contains(@class,'visually-hidden')]").text.replace("out of 5 stars","").replace("Rated",""),
'username': review.find_element_by_xpath(".//div[contains(@class,'ugc-author')]").text,
'userurl':"NA",
'title':review.find_element_by_xpath(".//h4[contains(@class,'c-section-title review-title heading-5 v-fw-medium')]").text,
'review_text':review.find_element_by_xpath(".//div[contains(@class,'ugc-review-body')]//p[contains(@class,'pre-white-space')]").text,
'permalink': "NA",
'reviewlocation': "NA",
'reviewdate': this_review_datetime,
'subproductname': "NA",
'subproductlink': "NA",
}
item_list.append(item)
except:
break