I have the following problem:
I have a pd Dataframe in which there are three columns, a datetime64 timestamp, and two columns each being an integer value. The table basically looks like the following:
| Timestamp | Integer1 | Integer2 |
|---|---|---|
| 2022-09-06 17:02:37.702173 | 0 | 1 |
| 2022-09-06 17:02:38.087692 | 0 | 2 |
| 2022-09-06 17:02:38.706589 | 0 | 1 |
| 2022-09-06 17:02:39.081571 | 0 | 2 |
The two integer columns together represent a state, so there would be two different states in the example 0-1 and 0-2.
In reality, there are several more states and, of course, timestamps. A new entry is written to the table approx. 15 times per second with the current timestamp and state of the system.
The task is now analyzing such a "system log", which includes calculating how much of the total time, the system was in each state.
So for a 20 minute trace and two different states i need a table with two rows for the states and a column with their representative times, adding up to 20 minutes in total.
Is there any way this can be achieved? Thanks in advance!
CodePudding user response:
See if this works:
import pandas as pd
# == Create an Example DataFrame ==========================================
df = pd.DataFrame(
[
["2022-09-06 17:02:37", 0, 1],
["2022-09-06 17:02:38", 0, 2],
["2022-09-06 17:02:38", 0, 1],
["2022-09-06 17:02:39", 0, 2],
["2022-09-06 19:02:38", 0, 1],
["2022-09-06 19:02:39", 0, 2],
],
columns=[
"Timestamp",
"Integer1",
"Integer2",
],
).astype({"Timestamp": "datetime64[ns]"})
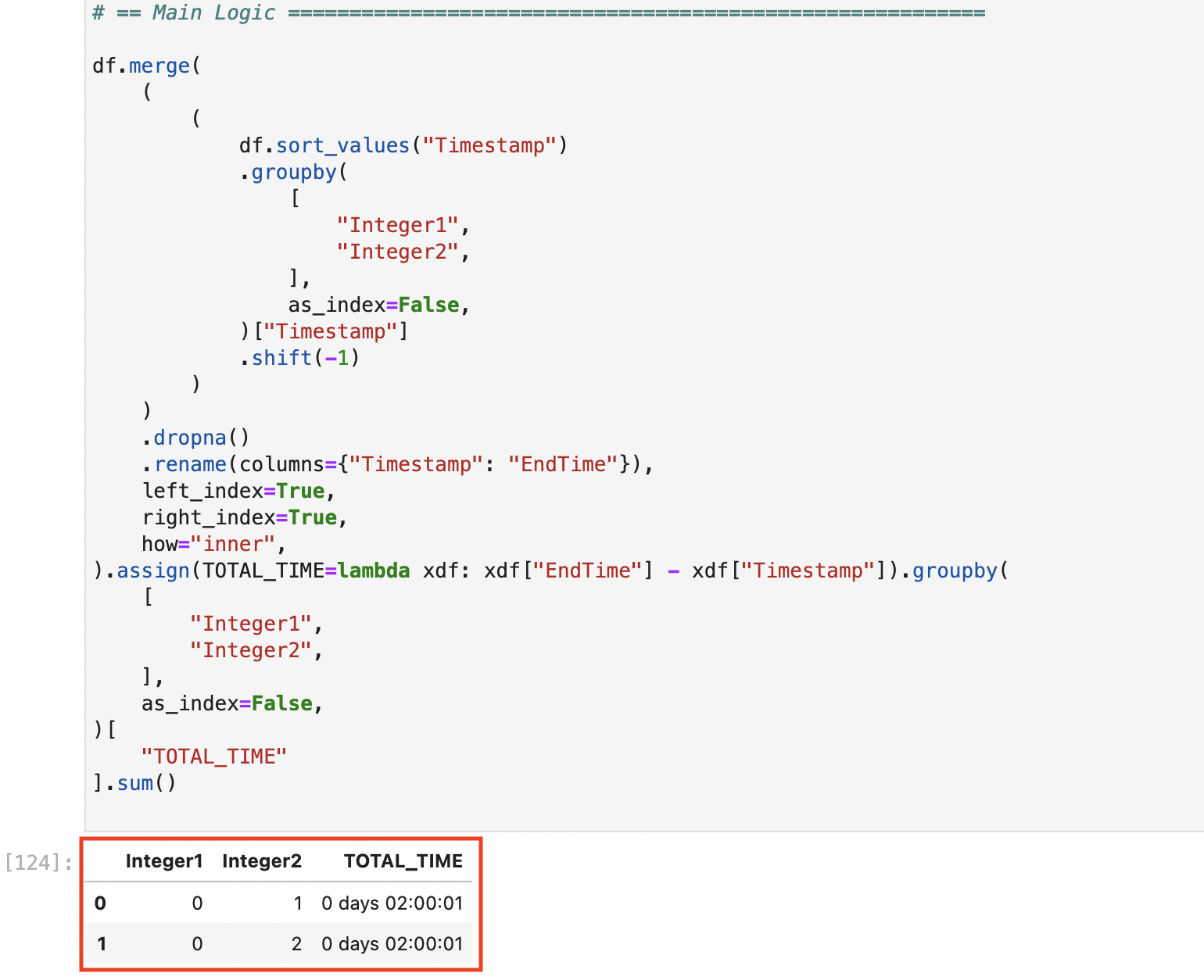
# == Main Logic =========================================================
df.merge(
(
(
df.sort_values("Timestamp")
.groupby(
[
"Integer1",
"Integer2",
],
as_index=False,
)["Timestamp"]
.shift(-1)
)
)
.dropna()
.rename(columns={"Timestamp": "EndTime"}),
left_index=True,
right_index=True,
how="inner",
).assign(TOTAL_TIME=lambda xdf: xdf["EndTime"] - xdf["Timestamp"]).groupby(
[
"Integer1",
"Integer2",
],
as_index=False,
)[
"TOTAL_TIME"
].sum()
# Expected output:
# Integer1 Integer2 TOTAL_TIME
# 0 0 1 0 days 02:00:01
# 1 0 2 0 days 02:00:01
CodePudding user response:
With df your dataframe you could try:
df["Duration"] = df["Timestamp"].diff().shift(-1)
res = df.groupby(["Integer1", "Integer2"], as_index=False)["Duration"].sum()
or
res = (
df["Timestamp"].diff().shift(-1)
.groupby([df["Integer1"], df["Integer2"]]).sum()
.rename("Duration").reset_index()
)
if you don't want to add a new column to df.
Result for your sample
Timestamp Integer1 Integer2
0 2022-09-06 17:02:37.702173 0 1
1 2022-09-06 17:02:38.087692 0 2
2 2022-09-06 17:02:38.706589 0 1
3 2022-09-06 17:02:39.081571 0 2
is
Integer1 Integer2 Duration
0 0 1 0 days 00:00:00.760501
1 0 2 0 days 00:00:00.618897