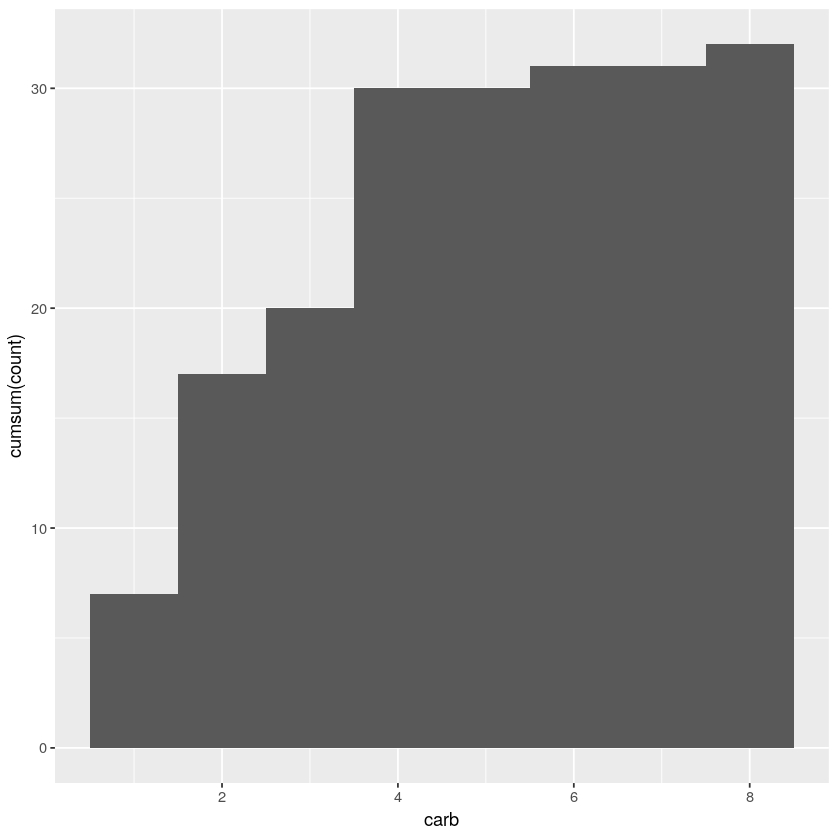
I am able to produce a cumulative histogram as below. Using mtcars as an example, each car has a certain number of carburetors. For each quantity of carburetors (x axis), the plot shows the number of cars with less than that many carburetors. I would like to produce a plot which shows the number of cars with greater than that many carburetors.
This link provides further explanation
Thanks!
mtcars %>%
ggplot(aes(carb))
geom_histogram(aes(y = cumsum(..count..)))
CodePudding user response:
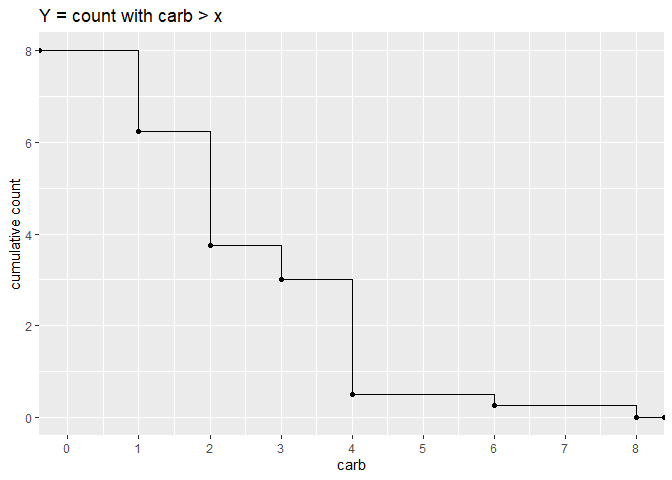
You can use 1 - stat_ecdf but transform density to count by multiplying by the number of values such that the y value at any given x represents the number of observations greater than that value of x. I'm showing the points to help illustrate the actual y value at each x since the geom = "step" somewhat obscures it.
This code uses the special variables computed within ggplot with the ..y.. syntax. I don't know if this is formally documented anywhere but it is described in this post on StackOverflow. It basically prevents you from having to perform these calculations outside of the ggplot() call.
library(tidyverse)
mtcars %>%
ggplot(aes(carb))
stat_ecdf(aes(y = (1 - ..y..) * length(..y..)), geom = "point")
stat_ecdf(aes(y = (1 - ..y..) * length(..y..)), geom = "step")
scale_x_continuous(limits = c(0, NA), breaks = 0:8)
ggtitle("Y = count with carb > x")
ylab("cumulative count")
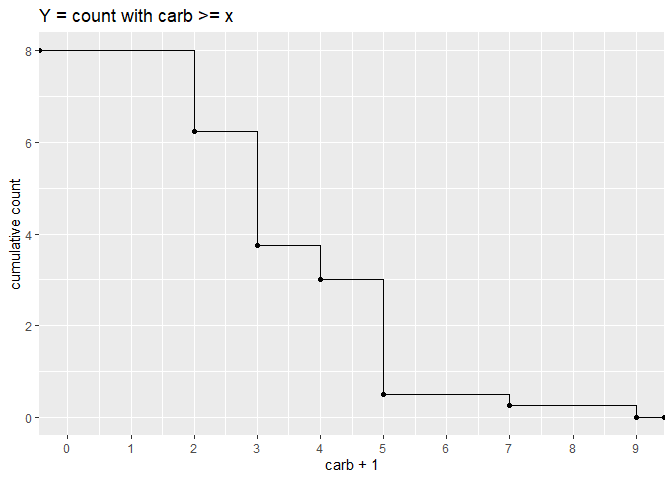
To get the count greater than or equal to you could modify the code to shift the ecdf by 1.
mtcars %>%
ggplot(aes(carb 1))
stat_ecdf(aes(y = (1 - ..y..) * length(..y..)), geom = "point")
stat_ecdf(aes(y = (1 - ..y..) * length(..y..)), geom = "step")
scale_x_continuous(limits = c(0, NA), breaks = 0:9)
ggtitle("Y = count with carb >= x")
ylab("cumulative count")
Created on 2022-09-29 by the reprex package (v2.0.1)
CodePudding user response:
Like this?
library(tidyverse)
mtcars |>
select(disp) |>
ggplot(aes(disp, y = 1 - ..y..))
stat_ecdf()