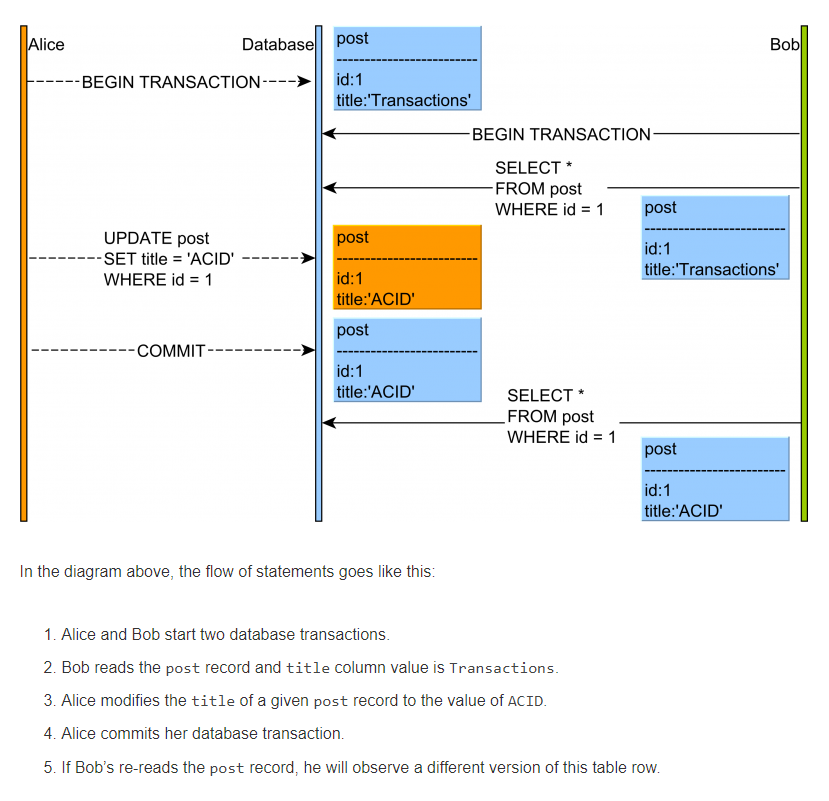
I read 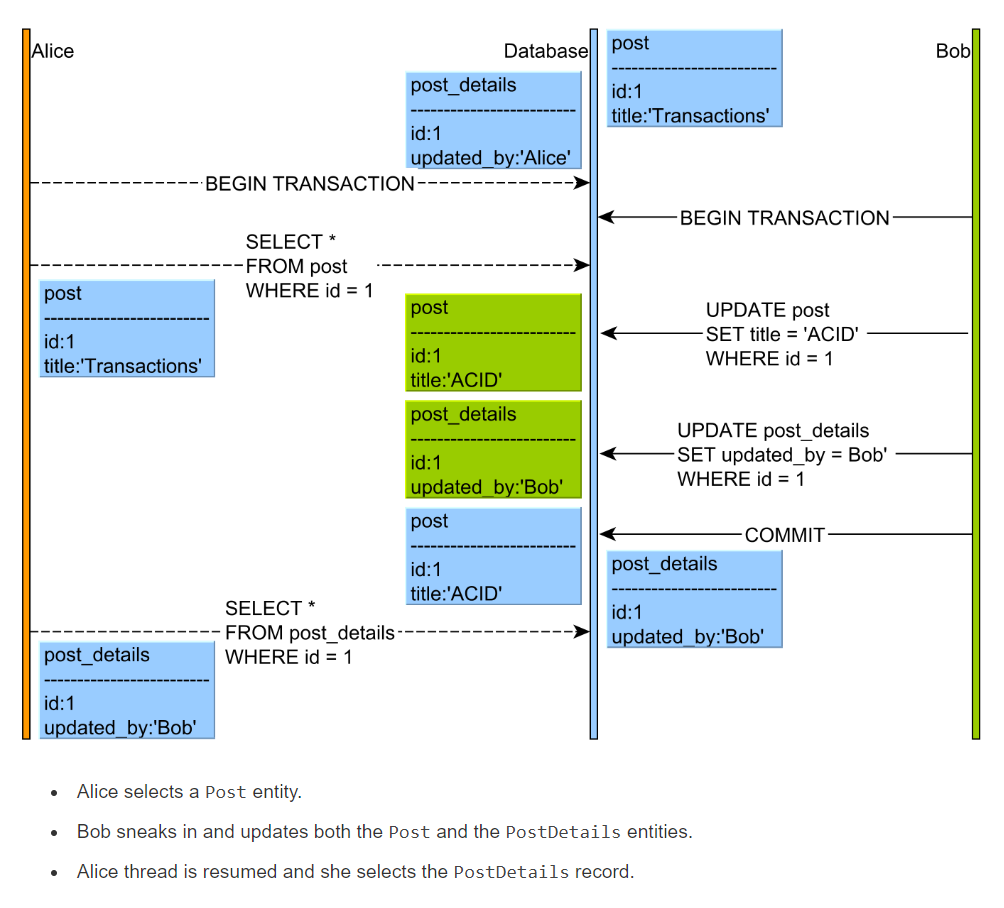
Non-repeatable read:
But, I cannot differentiate between read skew and non-repeatable read and basically, it seems like both can be prevented with REPEATABLE READ or SERIALIZABLE isolation level.
My questions:
What is the difference between read skew and non-repeatable read?
Can read skew and non-repeatable read be both prevented by
REPEATABLE READorSERIALIZABLE?
CodePudding user response:
We have two data - let x and y, and there is a relation between them.(e.g parent/child)
Transaction T1 reads x, and then a second transaction T2 updates x and y to new values and commits. If now T1 reads y, it may see an inconsistent state, and therefore produce an inconsistent state as output.
Acceptable consistent states:
x and y
x* and y*
Note: * denotes the updated value of variable
When x and y are the same data, meaning to read them, need to execute the same query. I guess, it leads to problem of non-repeatable.
IMHO, even if we may call read skew is generalization form of non-repeatable problem.
2.
Serializable isolation level permits transactions to run concurrently, it creates the effect that transactions are running in serial order.: read skew/non-repeatable prevented
Repeatable read isolation level guarantees that each transaction will return the same row regardless of how many times executed. From the definition, it seems read-skew may not be prevented. Without knowing how it is implemented, it is hard to claim anything.
Todays, DBMS engines use different approaches- concurrency control strategies to implement REPEATABLE Isolation level.
e.g Postgres use database snapshot(consistent view) to implement REPEATABLE READ Isolation level. -will prevent read skew
Other engines may use lock based concurrency control mechanisms to implement it. - may not prevent read skew.
CodePudding user response:
Non-repeatable read(fuzzy read) is that a transaction reads the same row at least twice but the same row's data is different between the 1st and 2nd reads because other transactions update the same row's data and commit at the same time(concurrently). *I explains more about Non-repeatable read in What is the difference between Non-Repeatable Read and Phantom Read?
Read skew is that with two different queries, a transaction reads inconsistent data because between the 1st and 2nd queries, other transactions insert, update or delete data and commit. Finally, an inconsistent result is produced by the inconsistent data.
There are the examples of read skew below which you can do with MySQL and 2 command prompts.
For these examples of read skew below, you need to set READ COMMITTED isolation level to occur read skew:
SET GLOBAL TRANSACTION ISOLATION LEVEL READ COMMITTED;
SET SESSION TRANSACTION ISOLATION LEVEL READ COMMITTED;
And, there is "bank_account" table with "id", "name" and "balance" as shown below:
<"bank_account" table>
| id | name | balance |
|---|---|---|
| 1 | John | 600 |
| 2 | Tom | 400 |
These steps below shows read skew. *300 is transferred from John's balance to Tom's balance. Then from Tom's balance, T1 reads 100 instead of 400. Finally, 600 100 = 700 in the total of John's and Tom's balances:
| Flow | Transaction 1 (T1) | Transaction 2 (T2) | Explanation |
|---|---|---|---|
| Step 1 | BEGIN; |
T1 starts. | |
| Step 2 | BEGIN; |
T2 starts. | |
| Step 3 | SELECT balance FROM bank_account WHERE id = 1;600 |
T1 reads "600". | |
| Step 4 | UPDATE bank_account set balance = 900 WHERE id = 1; |
T2 updates "600" to "900" because "300" is transferred to Tom's balance. | |
| Step 5 | UPDATE bank_account set balance = 100 WHERE id = 2; |
T2 updates "400" to "100" because "300" is transferred from John's balance. | |
| Step 6 | COMMIT; |
T2 commits. | |
| Step 7 | SELECT balance FROM bank_account WHERE id = 2;100 |
T1 reads "100" instead of "400" after T2 commits. | |
| Step 8 | 600 100 = 700 | T1 gets "700" instead of "1000".*Read skew occurs. |
|
| Step 9 | COMMIT; |
T1 commits. |
These steps below also shows read skew. *300 is withdrawn by Tom. Then, T1 reads 700 instead of 1000. Finally, 600 100 = 700 in the total of John's and Tom's balances:
| Flow | Transaction 1 (T1) | Transaction 2 (T2) | Explanation |
|---|---|---|---|
| Step 1 | BEGIN; |
T1 starts. | |
| Step 2 | BEGIN; |
T2 starts. | |
| Step 3 | SELECT balance FROM bank_account WHERE id = 1;600 |
T1 reads "600". | |
| Step 4 | UPDATE bank_account set balance = 100 WHERE id = 2; |
T2 updates "400" to "100" because "300" is withdrawn from Tom's balance. | |
| Step 5 | COMMIT; |
T2 commits. | |
| Step 6 | SELECT balance FROM bank_account WHERE id = 2;100 |
T1 reads "100" instead of "400" after T2 commits. | |
| Step 7 | 600 100 = 700 | T1 gets "700" instead of "1000".*Read skew occurs. |
|
| Step 8 | COMMIT; |
T1 commits. |
In addition, this is also the example of read skew. There are "teacher" and "student" tables with "id", "name" as shown below:
<"teacher" table>
| id | name |
|---|---|
| 1 | John |
| 2 | Tom |
<"student" table>
| id | name |
|---|---|
| 1 | Anna |
| 2 | Sarah |
| 3 | David |
| 4 | Mark |
| 5 | Kai |
These steps below shows read skew. *Lisa, Peter and Roy are inserted to "student" table. Then, T1 reads 8 instead of 5. Finally, 2 8 = 9 in the total of teachers and students:
| Flow | Transaction 1 (T1) | Transaction 2 (T2) | Explanation |
|---|---|---|---|
| Step 1 | BEGIN; |
T1 starts. | |
| Step 2 | BEGIN; |
T2 starts. | |
| Step 3 | SELECT count(*) FROM teacher;2 |
T1 reads "2". | |
| Step 4 | INSERT INTO student values (6, "Lisa"), (7, "Peter"), (8, "Roy"); |
T2 inserts "Lisa", "Peter" and "Roy". | |
| Step 5 | COMMIT; |
T2 commits. | |
| Step 6 | SELECT count(*) FROM student;8 |
T1 reads "8" instead of "5" after T2 commits.*Read skew occurs!! |
|
| Step 7 | 2 8 = 10 | T1 gets "10" instead of "7".*Read skew occurs. |
|
| Step 8 | COMMIT; |
T1 commits. |
Read skew is prevented or not prevented in each isolation level on MySQL as shown below:
| Isolation level | Read skew |
|---|---|
| READ UNCOMMITTED | Not Prevented |
| READ COMMITTED | Not Prevented |
| REPEATABLE READ | Prevented |
| SERIALIZABLE | Prevented |