Can you help me what is the error in this code, the file does exist but I know you are looking for it in HDFS sc.textFile("/user/spark/archivo.csv")
Or why does this error occur?
execution
export PYSPARK_PYTHON=python3
export PYSPARK_DRIVER_PYTHON=python3
spark-submit --queue=OID Proceso_Match1.py
Python
import os
import sys
from pyspark.sql import HiveContext, Row
from pyspark import SparkContext, SparkConf
from pyspark.sql.functions import *
from pyspark.sql import functions as F
from pyspark.sql.types import *
if __name__ =='__main__':
conf=SparkConf().setAppName("Spark RDD").set("spark.speculation","true")
sc=SparkContext(conf=conf)
sc.setLogLevel("OFF")
sqlContext = HiveContext(sc)
#rddCentral = sc.textFile("hdfs:///user/spark/archivo.csv")
rddCentral = sc.textFile("/user/spark/archivo.csv")
rddCentralMap = rddCentral.map(lambda line : line.split(","))
print('paso 1')
dfCentral = sqlContext.createDataFrame(rddCentralMap, ["ROWID_CDR","DURACION","FECHA_LLAMADA","FECHA_LLAMADA_2","MATCH"])
dfCentral=dfCentral.withColumn("FECHA_LLAMADA_NUM",dfCentral.FECHA_LLAMADA_2.cast(IntegerType()))
dfCentral=dfCentral.withColumn("DURACION_NUM",dfCentral.DURACION.cast(IntegerType()))
dfCentral=dfCentral.withColumn("MATCH_NUM",dfCentral.MATCH.cast(IntegerType()))
sc.stop()
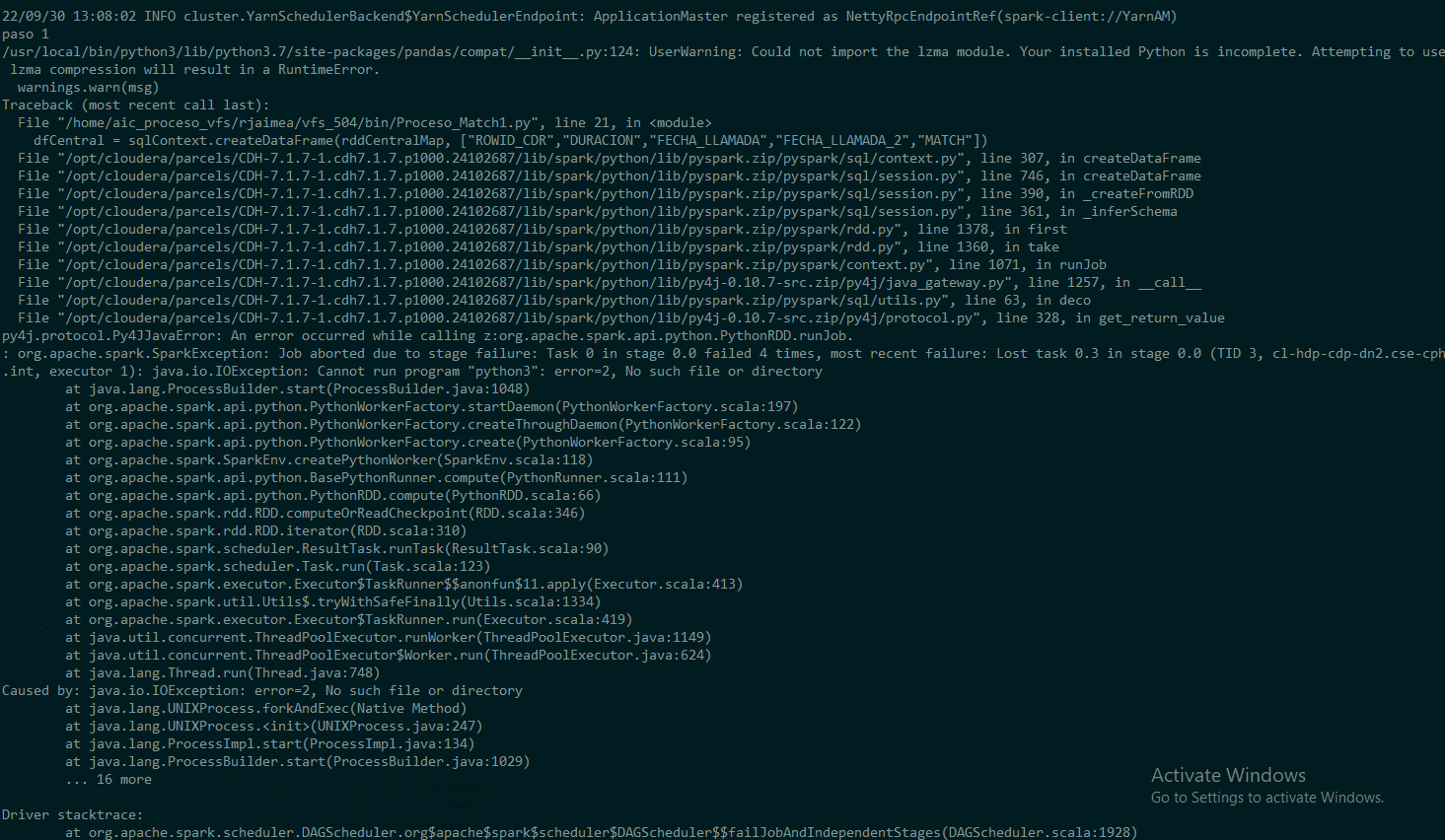
Error log
22/09/30 12:49:14 INFO cluster.YarnClientSchedulerBackend: SchedulerBackend is ready for scheduling beginning after reached minRegisteredResourcesRatio: 0.8
paso 1
/usr/local/bin/python3/lib/python3.7/site-packages/pandas/compat/__init__.py:124: UserWarning: Could not import the lzma module. Your installed Python is incomplete. Attempting to use lzma compression will result in a RuntimeError.
warnings.warn(msg)
Traceback (most recent call last):
File "/home/aic_proceso_vfs/rjaimea/vfs_504/bin/Proceso_Match1.py", line 21, in <module>
dfCentral = sqlContext.createDataFrame(rddCentralMap, ["ROWID_CDR","DURACION","FECHA_LLAMADA","FECHA_LLAMADA_2","MATCH"])
: org.apache.spark.SparkException: Job aborted due to stage failure: Task 0 in stage 0.0 failed 4 times, most recent failure: Lost task 0.3 in stage 0.0 (TID 3, cl-hdp-cdp-dn7.cse-cph.int, executor 1): java.io.IOException: Cannot run program "python3": error=2, No such file or directory
at java.lang.ProcessBuilder.start(ProcessBuilder.java:1048)
Caused by: java.io.IOException: error=2, No such file or directory
... 16 more
File HDFS
hdfs dfs -ls /user/spark
Found 3 items
drwxr-xr-x - spark hdfs 0 2022-07-25 10:11 /user/spark/.sparkStaging
-rw------- 3 hadoopadmin hdfs 21 2022-09-30 12:25 /user/spark/archivo.csv
drwxrwxrwt - spark spark 0 2022-09-30 12:33 /user/spark/driverLogs
CodePudding user response:
I'm not sure but it seems like you're mis-using the schema for the database being created
the line
dfCentral = sqlContext.createDataFrame(rddCentralMap, ["ROWID_CDR","DURACION","FECHA_LLAMADA","FECHA_LLAMADA_2","MATCH"])
takes the dict-like object that represents your dataframes data as the first parameter, and the schema for the second. You've just given a list of strings as the second argument.
In order to create the dataframe with some schema, you have to structure the fields that are in that list, then structure the list
so your program would look like this
import os
import sys
from pyspark.sql import HiveContext, Row
from pyspark import SparkContext, SparkConf
from pyspark.sql.functions import *
from pyspark.sql import functions as F
from pyspark.sql.types import * #where structType and structField come from
if __name__ =='__main__':
conf=SparkConf().setAppName("Spark RDD").set("spark.speculation","true")
sc=SparkContext(conf=conf)
sc.setLogLevel("OFF")
sqlContext = HiveContext(sc)
#rddCentral = sc.textFile("hdfs:///user/spark/archivo.csv")
rddCentral = sc.textFile("/user/spark/archivo.csv")
rddCentralMap = rddCentral.map(lambda line : line.split(","))
print('paso 1')
dfFields = ["ROWID_CDR","DURACION","FECHA_LLAMADA","FECHA_LLAMADA_2","MATCH"]
dfSchema = StructType([StructField(field_name, StringType(), True) for field_name in dfFields])
dfCentral = sqlContext.createDataFrame(rddCentralMap, dfSchema)
dfCentral=dfCentral.withColumn("FECHA_LLAMADA_NUM",dfCentral.FECHA_LLAMADA_2.cast(IntegerType()))
dfCentral=dfCentral.withColumn("DURACION_NUM",dfCentral.DURACION.cast(IntegerType()))
dfCentral=dfCentral.withColumn("MATCH_NUM",dfCentral.MATCH.cast(IntegerType()))
sc.stop()
Alternatively, the createDataFrame function takes an RDD as the first parameter. mapping the RDD created from reading the file may also be contributing to your issue