I have this especific DataFrame (which is all in one column);
data={'Name':['10000','Votes','12','10100', 'Votes', '13']}
df=pd.DataFrame(data)
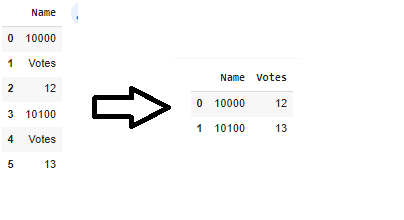
I want to create two new columns based on the value of the "votes" row.
In the first column, whenever "votes" appears, I want to create a column above the party numbers.
And in the second column, whenever "votes" appears, I'll take the values below. How i could do that in Pandas?
CodePudding user response:
Heres one way using np.roll, but it might not catch all of the edge cases
is_votes = df.Name=="Votes"
pd.DataFrame({'Name':df.loc[np.roll(is_votes,-1),"Name"].values , 'Votes':df.loc[np.roll(is_votes,1),"Name"].values})
# Name Votes
#0 10000 12
# 10100 13
CodePudding user response:
Without knowing how this is implemented, I can only give the "boilerplate" code at best.
import pandas as pd
data={'Name':['10000','Votes','12','10100', 'Votes', '13']}
Name = [data["Name"][i] for i in range(0,len(data["Name"]),3)]
Votes = [data["Name"][i] for i in range(2,len(data["Name"]),3)]
newData = {
"Name": Name,
"Votes": Votes
}
df = pd.DataFrame(newData)
print(df)
You would probably have to change this code around to work with your use case, but this is what I gathered from your question.
CodePudding user response:
Another possible solution, based on indexing and pandas.concat:
pd.concat([df.iloc[0:len(df):3].reset_index(drop=True), df['Name'].rename(
'Votes').iloc[2:len(df):3].reset_index(drop=True)], axis=1)
Output:
Name Votes
0 10000 12
1 10100 13