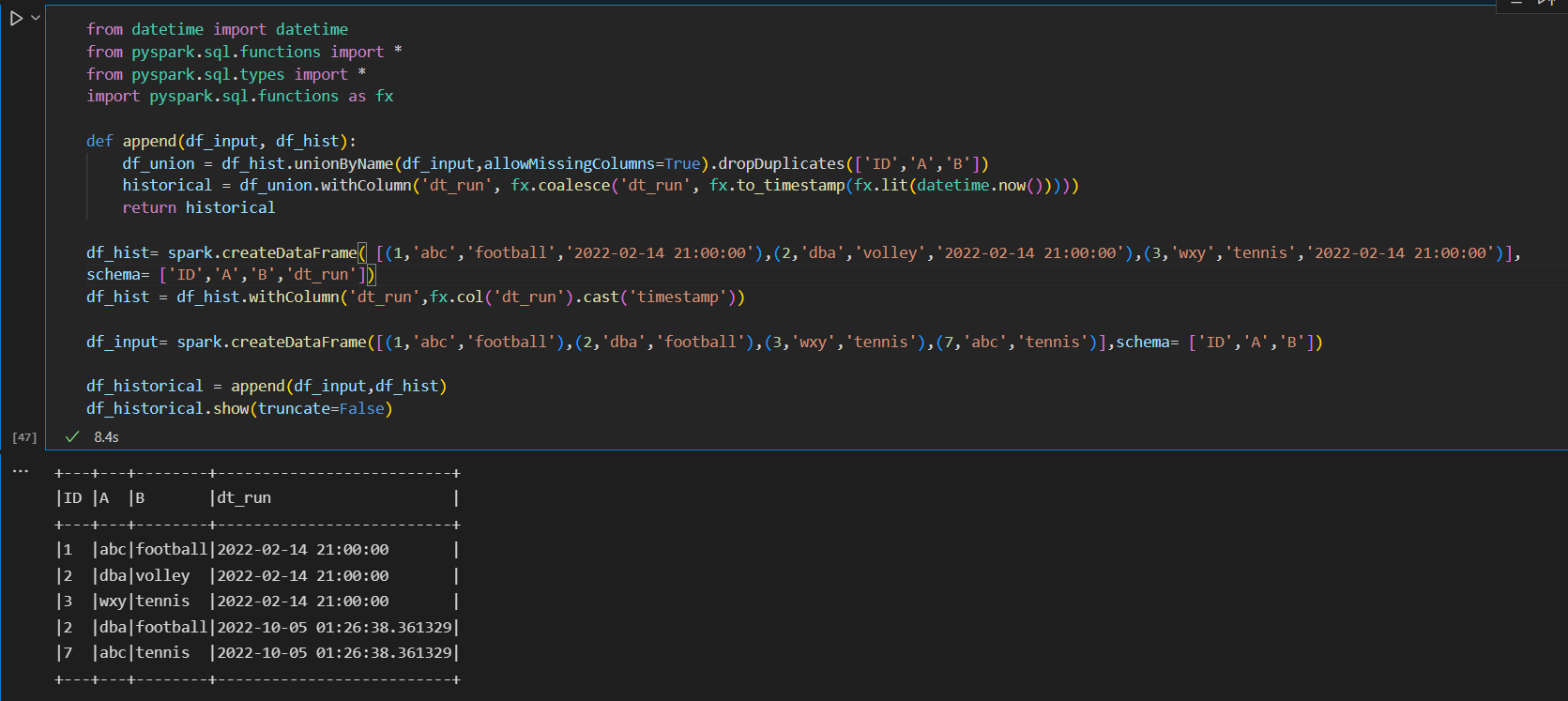
I would like to create a historical dataset on which I would like to add all NEW records of a dataset.
For NEW records I mean new records or modified records: all those that are the same for all columns except the 'reference_date' one.
I insert here the piece of code that allows me to do it on all columns, but I can't figure out how to implement the exclusion condition of a column.
Inputs:
historical (previous):
| ID | A | B | dt_run |
|---|---|---|---|
| 1 | abc | football | 2022-02-14 21:00:00 |
| 2 | dba | volley | 2022-02-14 21:00:00 |
| 3 | wxy | tennis | 2022-02-14 21:00:00 |
input_df (new data):
| ID | A | B |
|---|---|---|
| 1 | abc | football |
| 2 | dba | football |
| 3 | wxy | tennis |
| 7 | abc | tennis |
DESIRED OUTPUT (new records in bold)
| ID | A | B | dt_run |
|---|---|---|---|
| 1 | abc | football | 2022-02-14 21:00:00 |
| 2 | dba | volley | 2022-02-15 21:00:00 |
| 3 | wxy | tennis | 2022-02-01 21:00:00 |
| 2 | dba | football | 2022-03-15 14:00:00 |
| 7 | abc | tennis | 2022-03-15 14:00:00 |
My code which doesn't work:
@incremental(snapshot_inputs=['input_df'])
@transform(historical = Output(....), input_df = Input(....))
def append(input_df, historical):
input_df = input_df.dataframe().withColumn('dt_run', F.to_timestamp(F.lit(datetime.now())))
historical = historical.write_dataframe(dataset_input_df.distinct()\
.subtract(historical.dataframe('previous', schema=input_df.schema)))
return historical
CodePudding user response:
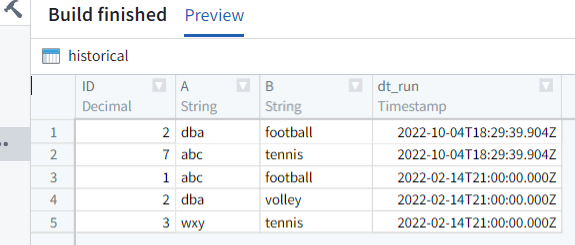
I've tested the following script and it works. In the following example, you don't need to drop/select columns. Using withColumn you create the missing column in input_df and also change the values in the existing column in historical. This way you can safely do subtract on the whole dataframe. Later, since you append the data rows, the old historical rows will stay intact with their old timestamps.
from transforms.api import transform, Input, Output, incremental
from pyspark.sql import functions as F
from datetime import datetime
@incremental(snapshot_inputs=['input_df'])
@transform(
historical=Output("...."),
input_df=Input("....")
)
def append(input_df, historical):
now = datetime.now()
df_inp = input_df.dataframe().withColumn('dt_run', F.to_timestamp(F.lit(now)))
df_hist = historical.dataframe('previous', df_inp.schema).withColumn('dt_run', F.to_timestamp(F.lit(now)))
historical.write_dataframe(df_inp.subtract(df_hist))
CodePudding user response:
You can use code similar to what is found