How can I implement this Pyspark code with Pandas Dataframes?
result = df.join(df2, df.name.contains(df2.text), "left")
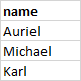
df
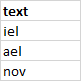
df2
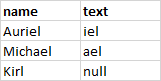
result
P.D: df and df2 are Big Data tables
Thank you very much in advance
CodePudding user response:
considering ops added constrain of scalability, i solved this with a lambda and a helper function
import pandas as pd
def helper(str1, str2):
out = 'null'
if str2 in str1:
out = str2
return out
names = ['auriel', 'michael', 'karl']
text = ['iel', 'ael', 'nov']
df = pd.DataFrame(names, columns=['name'])
df2 = pd.DataFrame(text, columns=['text'])
result = pd.DataFrame(zip(df.name, df2.text), columns=['name', 'text'])
result['text'] = result.apply(lambda x: helper(x[0], x[1]), axis=1)
print(result)
name text
0 auriel iel
1 michael ael
2 karl null
CodePudding user response:
Iam not sure if text will always be the last three characters. I therefore slice name using the text column. If its going to be always last three characters, then we can simplify it.
new = (df.withColumn('text',regexp_extract('name', ('|').join(df1.select('text').rdd.flatMap(lambda x:x).collect()), 0))#Use df1 column to slice name and create join column
.join(df1, how='left', on='text')#Join
).show()