I have a vector-type spatial data file for the streets of a given municipality and another file with raster-type spatial data with the slope of the terrain.
My goal is to cross the two data to find out which stretches have the steepest streets.
If both were data of type sf, I would use the st_intersection function. But how to proceed when the data are of different types?
My ultimate goal is to generate spatial data in vector form with a column indicating the slope of that stretch.
Reproducible example:
library(elevatr)
library(terra)
library(geobr)
library(osmdata) # package for working with streets
# 2 - get the municipality shapefile (vectorized spatial data)
municipality_shape <- read_municipality(code_muni = 3305802)
# 3 - get the raster topographical data
t <- elevatr::get_elev_raster(locations = municipality_shape,
z = 10, prj = "EPSG:4674")
obj_raster <- rast(t)
# 4 - calculate the slope
aspect <- terrain(obj_raster, "aspect", unit = "radians")
slope <- terrain(obj_raster, "slope", unit = "radians")
hillshade <- shade(slope, aspect)
# 5 - get the streets data
getbb("Teresópolis")
big_streets <- getbb("Teresópolis") |>
opq() |> # função que faz a query no OSM
add_osm_feature(key = "highway", # selecionar apenas ruas
value = "primary") |> # característica das ruas
osmdata_sf() # retorna a query como um objeto sf
# 6 - intersects the raster hillshade object with the sf object from streets available in big_streets$osm_lines$geometry.
CodePudding user response:
If you just want to extract the streets, subset out the linestrings:
big_streets <- getbb("Teresópolis")%>%
opq()%>% # função que faz a query no OSM
add_osm_feature(key = "highway", # selecionar apenas ruas
value = "primary") %>% # característica das ruas
osmdata_sf() %>%
osm_poly2line() %>%
`[[`("osm_lines")
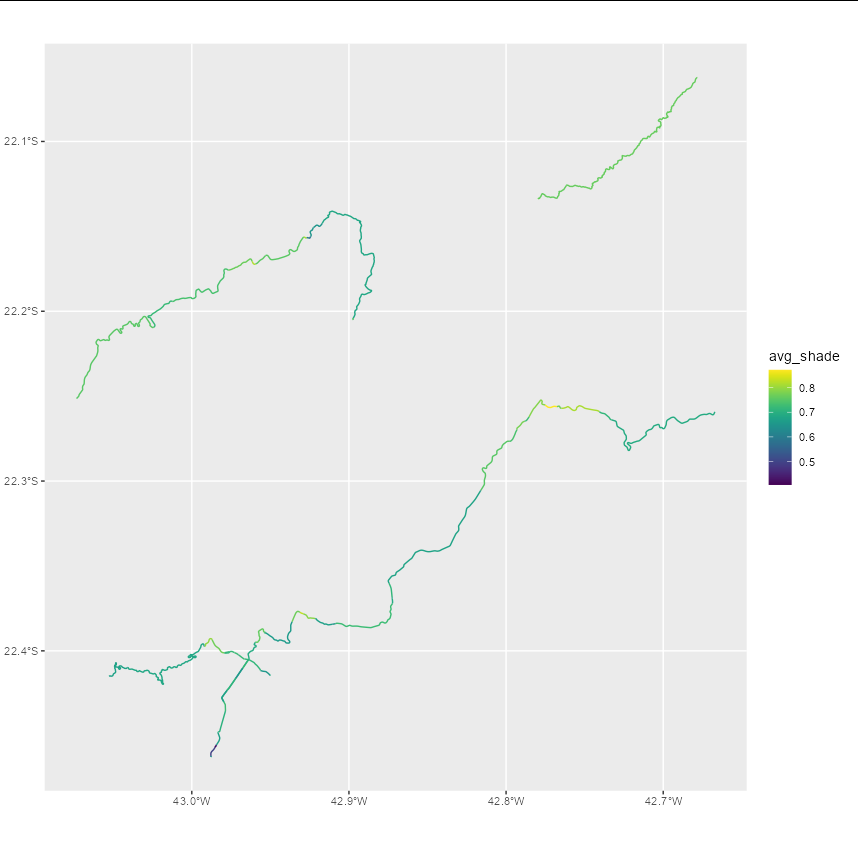
Now for each street, use extract to get the data corresponding to each linestring. You will need to average this so that there is a single average value for each street (though you could equally get the maximum slope if you wanted)
big_streets$avg_shade <- sapply(big_streets$geometry, function(x) {
mean(extract(hillshade, vect(x))[[2]])
})
Now big_streets has an extra column that gives you the average value of shade along each street. We can see what this looks like:
ggplot(big_streets) geom_sf(aes(color = avg_shade)) scale_color_viridis()