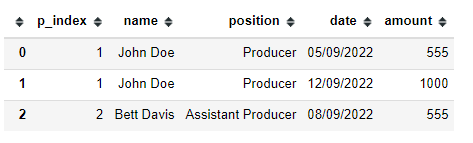
I have some big Excel files like this (note: other variables are omitted for brevity):
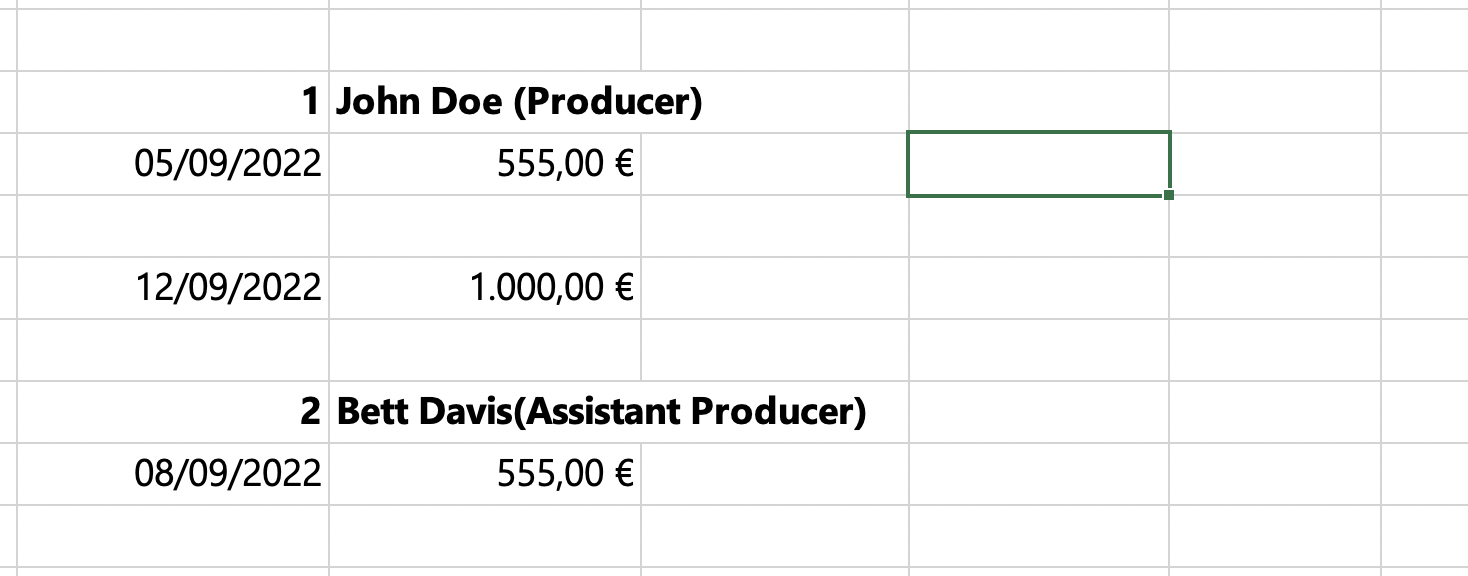
and would need to build a corresponding Pandas DataFrame with the following structure.

I am trying to develop a Pandas code for, at least, parsing the first column and transposing the id and the full of each user. Could you help with this?
CodePudding user response:
The way that I would tackle it, and I am assuming there are likely to be more efficient ways, is to import the excel file into a dataframe, and then iterate through it to grab the details you need for each line. Store that information in a dictionary, and append each formed line into a list. This list of dictionaries can then be used to create the final dataframe.
Please note, I made the following assumptions:
- Your excel file is named 'data.xlsx' and in the current working directory
- The index next to each person increments by one EVERY time
- All people have a position described in brackets next to the name
- I made up the column names, as none were provided
import pandas as pd
# import the excel file into a dataframe (df)
filename = 'data.xlsx'
df = pd.read_excel(filename, names=['col1', 'col2'])
# remove blank rows
df.dropna(inplace=True)
# reset the index of df
df.reset_index(drop=True, inplace=True)
# initialise the variables
counter = 1
name_pos = ''
name = ''
pos = ''
line_dict = {}
list_of_lines = []
# iterate through the dataframe
for i in range(len(df)):
if df['col1'][i] == counter:
name_pos = df['col2'][i].split(' (')
name = name_pos[0]
pos = name_pos[1].rstrip(name_pos[1][-1])
p_index = counter
counter = 1
else:
date = df['col1'][i].strftime('%d/%m/%Y')
amount = df['col2'][i]
line_dict = {'p_index': p_index, 'name': name, 'position': pos, 'date':date, 'amount': amount}
list_of_lines.append(line_dict)
final_df = pd.DataFrame(list_of_lines)
OUTPUT: