I'm Making a decision tree based on the iris dataset. Out professor asked us to select 40 data points from each iris type. Which is why I ran train_test_split 3 times for each flower type. Then I'm supposed to Kfold the Training set. As there are 3 flower types (with 4 attributes like sepal length/width) and 40 data points per type my final training set should be 120 x 4.
My code generates 3 40 x 4 data frames (x_train_0,x_train_1,x_train_2 etc.) but when I try to combine them using concat I get a data frame that's 30 x 4 instead of the expected 120 x 4.
Here's my code:
from sklearn import datasets
from sklearn.model_selection import StratifiedKFold
from sklearn.model_selection import train_test_split
# from sklearn.model_selection import cross_val_score
iris = datasets.load_iris()
# Create VALIDATION Data Set
x = pd.DataFrame(data = iris['data'], columns = iris['feature_names'])
y = pd.DataFrame(data = iris['target'], columns = ['target'])
# Create TEST/TRAINING sets
iris_0_index = y[y['target'] == 0]
iris_1_index = y[y['target'] == 1]
iris_2_index = y[y['target'] == 2]
iris_0 = x[x.index.isin(iris_0_index.index)]
iris_1 = x[x.index.isin(iris_1_index.index)]
iris_2 = x[x.index.isin(iris_2_index.index)]
x_train_0, x_test_0, y_train_0, y_test_0 = train_test_split(iris_0, iris_0_index, test_size= 0.8)
x_train_1, x_test_1, y_train_1, y_test_1 = train_test_split(iris_1, iris_1_index, test_size= 0.8)
x_train_2, x_test_2, y_train_2, y_test_2 = train_test_split(iris_2, iris_2_index, test_size= 0.8)
x_train = pd.concat([x_train_0,x_train_1,x_train_2])
Thanks!!
In response to @NickODell, I'm getting conflicting answers for the shape of the data frame. Functionally its 10 x 4 but in vscode's debug menu its 40 x 4
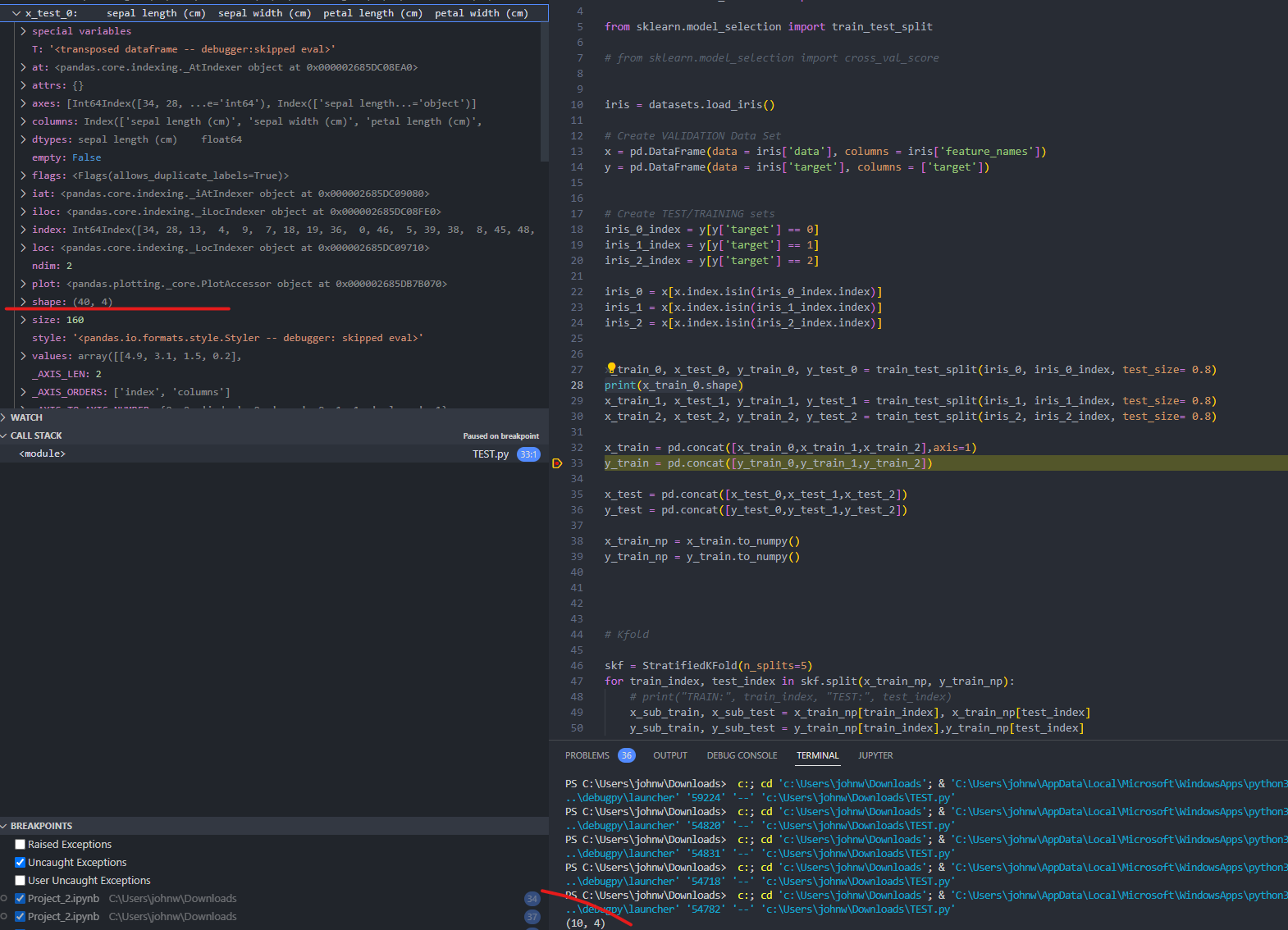
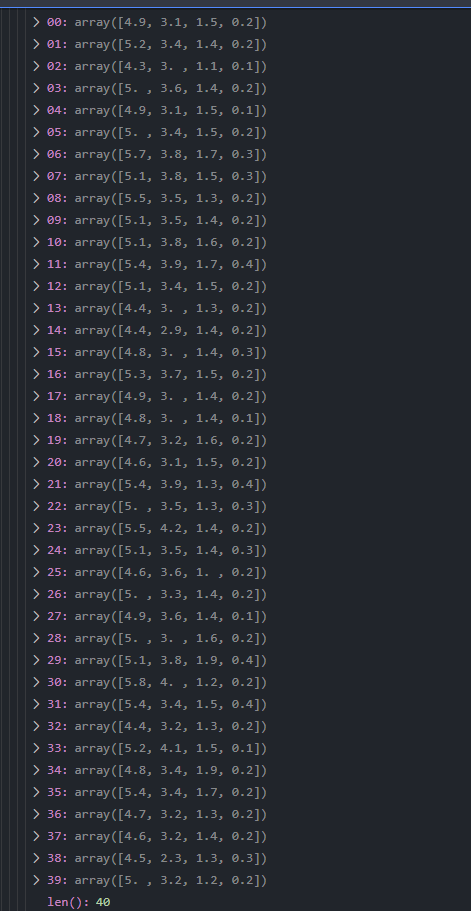
CodePudding user response:
My code generates 3 40 x 4 data frames (x_train_0,x_train_1,x_train_2 etc.)
Actually, it generates three 10 x 4 data frames.
>>> print([df.shape for df in [x_train_0,x_train_1,x_train_2]])
[(10, 4), (10, 4), (10, 4)]
CodePudding user response:
If I correctly understand your goal of vertically concactenating the three dataframes, then setting axis=0 (axis=1 for horizontal) should lead to the expected output:
x_train_0 = pd.DataFrame({'col1': [1, 2], 'col2': [3, 4]})
x_train_1 = pd.DataFrame({'col1': [5, 6], 'col2': [7, 8]})
x_train_2 = pd.DataFrame({'col1': [9, 10], 'col2': [11, 12]})
x_train = pd.concat([x_train_0,x_train_1,x_train_2], axis=0)
x_train
output
col1 col2
0 1 3
1 2 4
0 5 7
1 6 8
0 9 11
1 10 12
CodePudding user response:
print(f"{x.shape = }")
print(f"{y.shape = }")
print(f"{iris_0.shape = }")
print(f"{iris_1.shape = }")
print(f"{iris_2.shape = }")
print(f"{x_test_0.shape = }")
print(f"{x_test_1.shape = }")
print(f"{x_test_2.shape = }")
print(f"{x_train_0.shape = }")
print(f"{x_train_1.shape = }")
print(f"{x_train_2.shape = }")
print(f"{x_train.shape = }")
x.shape = (150, 4)
y.shape = (150, 1)
iris_0.shape = (50, 4)
iris_1.shape = (50, 4)
iris_2.shape = (50, 4)
x_test_0.shape = (40, 4)
x_test_1.shape = (40, 4)
x_test_2.shape = (40, 4)
x_train_0.shape = (10, 4)
x_train_1.shape = (10, 4)
x_train_2.shape = (10, 4)
x_train.shape = (30, 4)