I have a DataFrame with the following configuration:
data mov_avg
Timestamp
2019-12-02 00:00:00-05:00 1.0 1.0
2019-12-03 00:00:00-05:00 1.0 1.0
2019-12-04 00:00:00-05:00 1.0 1.0
2019-12-05 00:00:00-05:00 1.0 1.0
2019-12-06 00:00:00-05:00 1.0 1.0
... ... ...
2022-06-21 00:00:00-04:00 1.0 1.0
2022-06-22 00:00:00-04:00 1.0 1.0
2022-06-23 00:00:00-04:00 1.0 1.0
2022-06-24 00:00:00-04:00 1.0 1.0
2022-06-25 00:00:00-04:00 1.0 1.0
Most data values are equal to 1, and I'm trying to find periods where:
mov_avgis lower than 1 for more than X timestamps (e.g. X=7)
AND
- There are at least Y values in
datalower than 1 (e.g. Y=5)
I managed to get the first of the two conditions via the following code:
# Create a column for timestamps that have mov_avg lower than 1
df['pos_out'] = df['mov_avg'] < 1
# Create 'cons_day_out' column that return # of consecutive days with mov_avg lower than 1
g = df['pos_out'].ne(df['pos_out'].shift()).cumsum()
df['cons_days_out'] = df.groupby(g)['pos_out'].transform('size') * np.where(df['pos_out'], 1, 0)
# Return 'True' for periods with more than 7 days with mov_avg lower than 1
min_out_days = 7
df['out_cond1'] = (df['cons_days_out'] > min_out_days)
but I can't find a way to check for the other condition.
EDIT: Snippet with dict to reproduce dataset 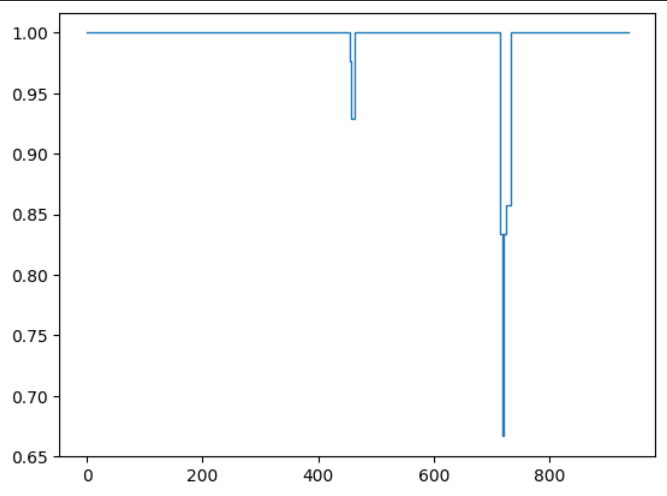
The sf_mov_avg object is of type staircase.Stairs. This is to the staircase library what Series is to pandas - it's the main workhorse. You can compare them, add them, multiply them etc. We can find out where it is less than 1 by simply doing sf_mov_avg < 1 which gives us back a boolean valued step function - it will be 1 everywhere it is true, and 0 otherwise. We can explore the step function in dataframe form using to_frame:
(sf_mov_avg < 1).to_frame()
which gives us the following pandas dataframe
start end value
0 -inf 0 NaN
1 0 456 0
2 456 464 1
3 464 714 0
4 714 733 1
5 733 937 0
6 937 inf NaN
We're only interested in those parts where the step function has value of 1 - but also where the intervals are strictly greater than 7, so let's identify those
cond1 = (sf_mov_avg < 1).to_frame().query("value == 1").query("end - start > 7")
cond1 looks like this
start end value
2 456 464 1
4 714 733 1
From here let's convert these intervals (which satisfy your first condition) to a pandas interval index:
cond1_intervals = pd.IntervalIndex.from_arrays(cond1["start"], cond1["end"], closed="left")
Next we'll create a boolean step function for whenever sf_data is less than 1, then we'll slice the step function by those intervals satisfying the first condition, then integrate. Since the step function is 0-1 valued, integrating tells us how many days are "true" (with respect to second condition).
cond2_candidates = (sf_data < 1).slice(cond1_intervals).integral()
cond2_candidates looks like this
[456, 464) 2
[714, 733) 5
dtype: int32
As you can see there is an interval with two days where df["data"] is less than 1, and another with 5 days. Filter, and pull out intervals where condition 2 is satisfied like so:
cond2_intervals = cond2_candidates[cond2_candidates >= 5].index
This gives you a pandas interval index
IntervalIndex([[714, 733)], dtype='interval[int64, right]')
Let's look at the original data between these index values for the first (and only) interval in this interval index
df.iloc[cond2_intervals[0].left: cond2_intervals[0].right]
which gives
data mov_avg
2021-11-15 00:00:00-05:00 1.000000 0.976190
2021-11-16 00:00:00-05:00 1.000000 0.833333
2021-11-17 00:00:00-05:00 1.000000 0.833333
2021-11-18 00:00:00-05:00 0.833333 0.833333
2021-11-19 00:00:00-05:00 0.000000 0.809524
2021-11-20 00:00:00-05:00 1.000000 0.666667
2021-11-21 00:00:00-05:00 1.000000 0.666667
2021-11-22 00:00:00-05:00 0.833333 0.690476
2021-11-23 00:00:00-05:00 0.000000 0.833333
2021-11-24 00:00:00-05:00 1.000000 0.833333
2021-11-25 00:00:00-05:00 1.000000 0.833333
2021-11-26 00:00:00-05:00 1.000000 0.857143
2021-11-27 00:00:00-05:00 1.000000 0.857143
2021-11-28 00:00:00-05:00 1.000000 0.857143
2021-11-29 00:00:00-05:00 1.000000 0.857143
2021-11-30 00:00:00-05:00 0.000000 0.857143
2021-12-01 00:00:00-05:00 1.000000 0.857143
2021-12-02 00:00:00-05:00 1.000000 0.857143
2021-12-03 00:00:00-05:00 1.000000 0.857143
You should be able to see that this section of the data satisfies your conditions.
In general we can filter the dataframe to include only the relevant data like so:
df[cond2_intervals.contains(range(len(df)))]
summary
sf_data = sc.Stairs.from_values(
initial_value=0,
values=df["data"].reset_index(drop=True),
)
sf_mov_avg = sc.Stairs.from_values(
initial_value=0,
values=df["mov_avg"].reset_index(drop=True),
)
sf_data = sf_data.clip(0,len(df))
sf_mov_avg = sf_mov_avg.clip(0,len(df))
cond1 = (sf_mov_avg < 1).to_frame().query("value == 1").query("end - start > 7")
cond1_intervals = pd.IntervalIndex.from_arrays(cond1["start"], cond1["end"], closed="left")
cond2_candidates = (sf_data < 1).slice(cond1_intervals).integral()
cond2_intervals = cond2_candidates[cond2_candidates >= 5].index
results = df[cond2_intervals.contains(range(len(df)))]
note: I am the author of staircase, feel free to ask any questions.