I know it sounds like a very simple problem but i am struggling to get the proper solution for this, I have a input dataframe, where i want to add a new column derived based on area group and simple arithmetic operation between amount and rate. I know i have to run aloop for each row to get the previous derived value to calculate next derived value:
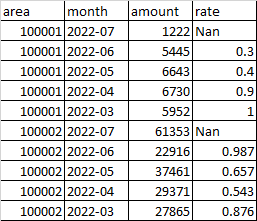
Output dataframe (added some comments in :
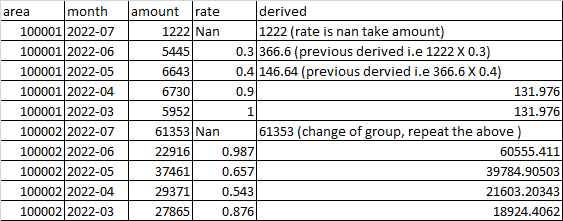
I am trying something like this:
def func(df):
for i in range(1, len(df)):
return (df['derived'].shift(1) * df['rate'])
df['derived'] = df['amount']
df['derived'] = df.groupby(['area']).apply(func)
But getting error:
ValueError: Buffer dtype mismatch, expected 'Python object' but got 'long'
CodePudding user response:
You can use a groupby.cumprod with custom groups:
m = df['rate'].isna()
df['derived'] = df['amount'].where(m, df['rate']).groupby(m.cumsum()).cumprod()
output: None provided as the data is not reproducible
CodePudding user response:
I created a dummy dataframe. Does this work on your data?
import pandas as pd
df = pd.DataFrame({"amount":[100,200,250,1002,3040,5000,10200,15489],
"rate":[None, 0.8,0.9,0.3,0.4,None,0.23,0.8]})
df = df.ffill().fillna(1)
df["derived"] = df.apply(lambda x: (np.where(x.name==0, x.amount * x.rate,
x.amount df.shift(1).loc[x.name].amount) * x.rate),
axis=1)