I have a CSV file, around 5k lines, with the following example:
apple,tea,salt,fish
apple,oranges,ketchup
...
salad,oreo,lemon
salad,soda,water
I need to extract only first line matching apple or salad and skip other lines where those words occur.
I can do something like this with regex, "apple|salad", but it will extract all the lines where those words are found.
The desired result is:
apple,tea,salt,fish
salad,oreo,lemon
I'm able to use REGEX in a text editor and OpenOffice Calc application.
CodePudding user response:
You could use the great 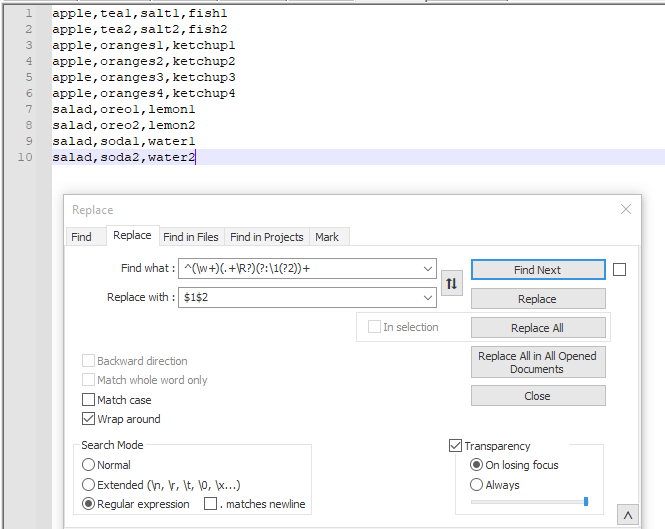
Screenshot (after):
CodePudding user response:
In Notepad repeatedly do a regular expression replace of ^(\w ,)(.*)\R\1.*$ with \1\2. Have "Wrap around" selected.
Explanation:
^ Match beginning of line
(\w ,) Match the leading word plus comma, save to capture group 1
(.*) Match the rest of the line, save to capture group 2
\R Match a line break
\1 Match the same leading word plus comma
.* Match the rest of the line
$ Match the end of the line
The replace string just keeps the first line, the second line is discarded.
Demonstration:
Starting with:
apple,tea1,salt1,fish1
apple,tea2,salt2,fish2
apple,oranges1,ketchup1
apple,oranges2,ketchup2
apple,oranges3,ketchup3
apple,oranges4,ketchup4
salad,oreo1,lemon1
salad,oreo2,lemon2
salad,soda1,water1
salad,soda2,water2
Doing a "Replace all" with the above expressions yields:
apple,tea1,salt1,fish1
apple,oranges1,ketchup1
apple,oranges3,ketchup3
salad,oreo1,lemon1
salad,soda1,water1
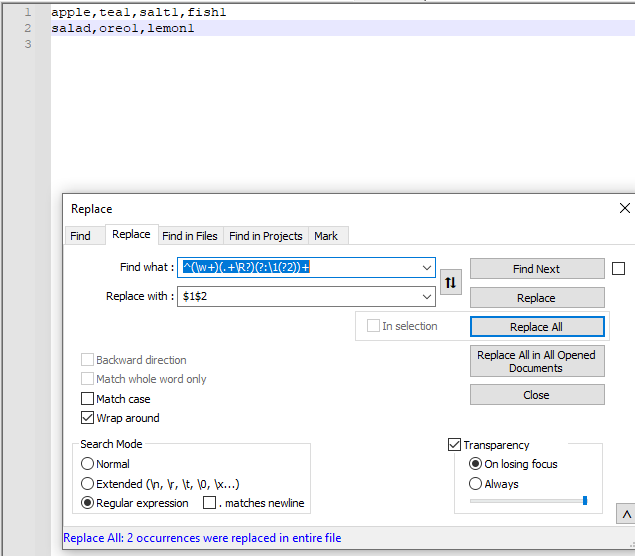
Two more clicks on "Replace all" yield:
apple,tea1,salt1,fish1
salad,oreo1,lemon1
Each press of "Replace all" removes approximately half of the unwanted lines.