Relatively new to Python here. I have a dataframe with three columns: Teams, Year and Medals_Won like so:
Teams Year Medals_Won
A 2009 Gold
A 2010 Silver
A 2011 Silver
A 2012 Bronze
A 2013 Gold
B 2009 Bronze
B 2010 Gold
B 2011 Bronze
B 2012 Silver
B 2013 Silver
C 2009 Silver
C 2010 Bronze
C 2011 Gold
C 2012 Gold
C 2013 Bronze
I want to take the Medals_Won column and split it based on the type of medals without upsetting the size and order of the first two columns like so (Missing values would be Null/NaN):
Teams Year Gold_Winner Silver_Winner Bronze_Winner
A 2009 Gold Null Null
A 2010 Null Silver Null
A 2011 Null Silver Null
A 2012 Null Null Bronze
A 2013 Gold Null Null
B 2009 Null Null Bronze
B 2010 Gold Null Null
B 2011 Null Null Bronze
B 2012 Null Silver Null
B 2013 Null Silver Null
C 2009 Null Silver Null
C 2010 Null Null Bronze
C 2011 Gold Null Null
C 2012 Gold Null Null
C 2013 Null Null Bronze
Can someone please help me in solving this problem? I tried to use the insert function with .loc (which did not work):
df.insert(2, 'Gold_Won', df.loc[df[Medals_Won] == 'Gold')
df.insert(3, 'Silver_Won', df.loc[df[Medals_Won] == 'Silver')
df.insert(4, 'Silver_Won', df.loc[df[Medals_Won] == 'Bronze')
CodePudding user response:
here is one way to do it
# get the dummy columns in a separate DF
dmy=pd.get_dummies(df['Medals_Won'])
# replace values with the column names
dmy=dmy.mul(dmy.columns).replace('','Null')
# combine the two DF
pd.concat([df, dmy],
axis=1
)
Teams Year Medals_Won Bronze Gold Silver
0 A 2009 Gold Null Gold Null
1 A 2010 Silver Null Null Silver
2 A 2011 Silver Null Null Silver
3 A 2012 Bronze Bronze Null Null
4 A 2013 Gold Null Gold Null
5 B 2009 Bronze Bronze Null Null
6 B 2010 Gold Null Gold Null
7 B 2011 Bronze Bronze Null Null
8 B 2012 Silver Null Null Silver
9 B 2013 Silver Null Null Silver
10 C 2009 Silver Null Null Silver
11 C 2010 Bronze Bronze Null Null
12 C 2011 Gold Null Gold Null
13 C 2012 Gold Null Gold Null
14 C 2013 Bronze Bronze Null Null
CodePudding user response:
You can do this two ways
df['Gold_Winner'] = None
df.loc[df.Medals_Won == 'Gold', 'Gold_Winner'] = 'Gold'
you can iterate
for medal_type in ['Gold', 'Silver', 'Bronze']:
df[f'{medal_type}_Winner'] = None
df.loc[df.Medals_Won == medal_type, f'{medal_type}_Winner'] = medal_type
a better way is to use pivot
df.pivot(index=['Teams', 'Year'], columns='Medals_Won', values='Medals_Won')
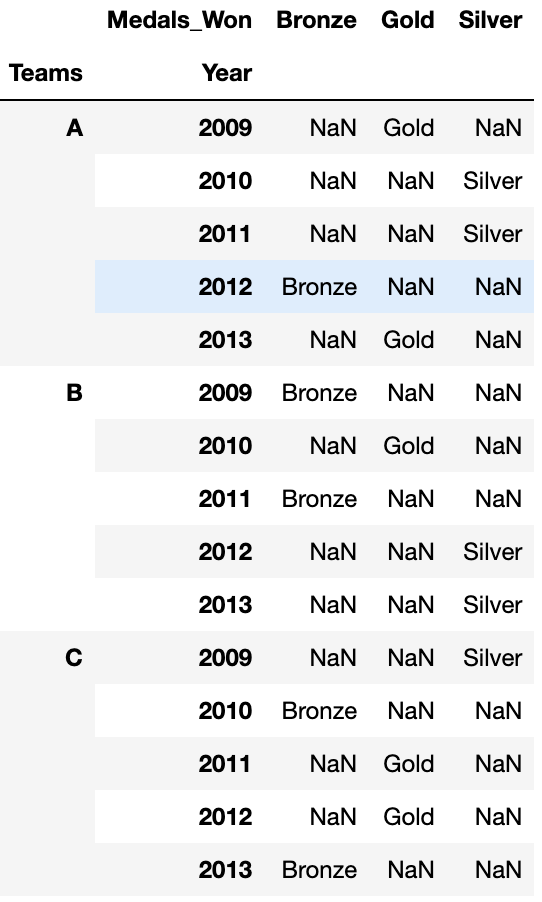
CodePudding user response:
If you have the dataframe loaded in as df, then I think the following code should get you what you're looking for:
df["Gold_Winner"] = df["Medals_Won"].apply(lambda x: "Gold" if x == "Gold" else None)
df["Silver_Winner"] = df["Medals_Won"].apply(lambda x: "Silver" if x == "Silver" else None)
df["Bronze_Winner"] = df["Medals_Won"].apply(lambda x: "Bronze" if x == "Bronze" else None)
df = df.drop(columns=["Medals_Won"])
It creates one column for each of the gold, silver, and bronze categories and then it drops the Medals_Won category.
CodePudding user response:
As you can see, there are lots of ways to achieve this. This one would hardly be the fastest in this case, but just for reference: you could use str.extract as follows:
tmp = df.Medals_Won.str.extract(r'(?P<Gold_Winner>Gold)|(?P<Silver_Winner>Silver)|(?P<Bronze_Winner>Bronze)')
df[tmp.columns] = tmp
df = df.drop('Medals_Won', axis=1)
print(df)
Teams Year Gold_Winner Silver_Winner Bronze_Winner
0 A 2009 Gold NaN NaN
1 A 2010 NaN Silver NaN
2 A 2011 NaN Silver NaN
3 A 2012 NaN NaN Bronze
4 A 2013 Gold NaN NaN
5 B 2009 NaN NaN Bronze
6 B 2010 Gold NaN NaN
7 B 2011 NaN NaN Bronze
8 B 2012 NaN Silver NaN
9 B 2013 NaN Silver NaN
10 C 2009 NaN Silver NaN
11 C 2010 NaN NaN Bronze
12 C 2011 Gold NaN NaN
13 C 2012 Gold NaN NaN
14 C 2013 NaN NaN Bronze